
Edit (June 30): Added reference to OpenAI function calling as intent classifier.
Large Language Models (LLMs) have been making headlines for quite some time now, thanks to their impressive capabilities in natural language understanding, summarization, translation, and even creative writing. Examples of popular LLMs making news include OpenAI's GPT series, Google's PaLM 2 & Med-PaLM 2, and Facebook's LLaMA. However, as LLMs become more powerful and widely adopted in various applications, ensuring their functionality, performance, reliability, safety, and security becomes a significant undertaking. We discussed some risks associated with generative AI applications before.
Due to the surge in large language model releases, there has been a notable increase in the deployment of chatbots and co-pilot applications tailored to specific business use cases.
To help navigate the complex world of testing LLMs, there are multiple frameworks, benchmarks, and tools that developers and researchers can leverage. Some notable frameworks and benchmarks include GLUE Benchmark, SuperGLUE Benchmark, OpenAI Moderation API, MMLU, EleutherAI LM Eval, OpenAI Evals, and more. These tools provide ample opportunities for assessing LLMs' abilities and limitations, thus contributing to more secure, safe, and ethical AI systems.
For developers building chatbot applications with LLMs, testing the performance of their applications (or prompts) is as crucial as testing any software. Several platforms have emerged to facilitate this process. For instance, TruEra has recently launched TruLens, an open-source software specifically designed to evaluate and iterate on applications built on LLMs. TruLens uses feedback functions to programmatically evaluate output from LLMs and analyze both the generated text and the response's metadata. In addition to ensuring safety, it is imperative to conduct functional testing of large language model applications.
We have developed a comprehensive set of guidelines to address the testing various components of a chatbot applications systematically. Let's look at some of the high-level components of a chatbot: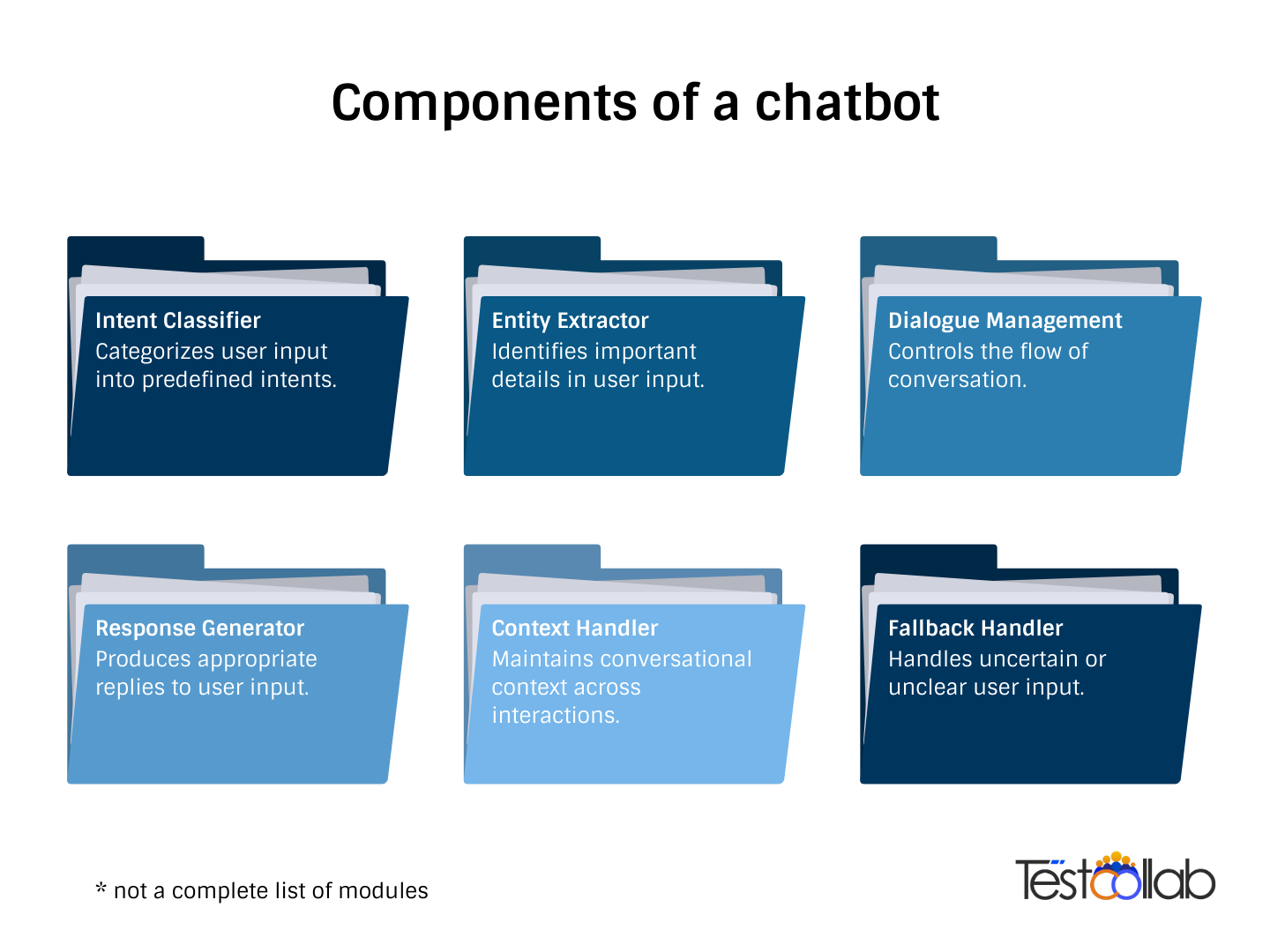
Consider the first module, the intent classifier, as a prime example. Here are some key areas you need to consider when performing QA on intent classifiers and other aspects of LLMs:
In the face of intricate testing scenarios, utilizing a tool such as Test Collab can greatly assist in managing and streamlining the entire process efficiently. Using this as an example, such key areas can be categorized in test suites as such:.png)
A more comprehensive approach to evaluating chatbot applications involves "red teaming," which is the practice of testing and probing AI systems, including LLMs, for potential security vulnerabilities and harmful outputs. Microsoft offers an introduction to red teaming LLMs and emphasizes assembling a diverse and experienced group of red teamers, conducting iterative exercises, and regularly reporting top findings to stakeholders.
In addition to these specialized tools and techniques, several evaluation frameworks like EleutherAI's lm-eval package provide robust and reproducible ways to evaluate LLMs. With over 200 evaluation tasks and support for various LLMs like GPT-2, GPT-3, Gpt-J, Gpt-Neo, and Gpt-NeoX, the package allows task development, customization, versioning, and decontamination to remove training data overlap. However, human evaluation still plays an essential part in assessing LLM performance, as it measures critical areas like creativity, humor, and engagement.
In conclusion, as LLMs and chatbot technology continues to evolve, the need to validate, evaluate, and ensure the safety and performance of these sophisticated models becomes increasingly vital. The frameworks, benchmarks, tools, and red teaming tactics discussed here provide developers and researchers with ample resources to assess and utilize LLMs responsibly.






