Playwright has earned its reputation as one of the best end to end testing tools available. It's fast, reliable, supports multiple browsers, and the developer experience is excellent. If you need to automate browser interactions, Playwright test automation is hard to beat.
But here's the problem nobody talks about until it's too late: Playwright doesn't capture, organize, or retain test evidence at scale.
It runs tests. It tells you pass or fail. It can generate a Playwright HTML report. But when your VP asks "show me proof that we tested the checkout flow across the last six releases" - you're on your own.
This isn't a knock on Playwright. It's a testing framework, not a test management system. The issue is that teams treat it as both, and the gaps only become visible when the stakes are highest: during audits, production incidents, or compliance reviews.
And now that AI coding agents are writing and running Playwright tests autonomously - via tools like Playwright CLI, Claude Code, and Cursor - the evidence gap just got 10x worse. More tests, more runs, more branches, more ephemeral reports. And nobody is there to manually curate what got tested.
What Playwright does well
Before getting into the gaps, let's acknowledge where Playwright testing shines.
Cross-browser automation. Chromium, Firefox, WebKit - all from a single API. No more maintaining separate test suites per browser.
Auto-waiting and reliability. Playwright's auto-wait mechanisms eliminate the flaky test problem that plagued earlier frameworks. Elements are waited for automatically before interactions.
Trace viewer and debugging. The built-in trace viewer captures DOM snapshots, network requests, and console logs during test execution. For debugging individual test failures, it's exceptional.
Playwright screenshots and video recording. You can configure Playwright to capture screenshots on failure and record video of test runs. The raw capability is there.
Parallel execution. Tests run in parallel by default, with isolated browser contexts. Fast feedback loops for developers.
For a development team running a few hundred tests in CI, this is everything you need. The problems emerge when you try to use Playwright reporting as your source of truth for test evidence across a growing organization.
Where Playwright reporting falls short at scale
Evidence is ephemeral
The Playwright HTML report is generated fresh on every test run. The previous report? Gone. Overwritten. Unless you've built custom infrastructure to archive reports from every CI pipeline run, you have no historical record.
This means:
- You can't compare test results across releases
- You can't prove a feature was tested three months ago
- You can't show an auditor a trail of evidence from the last quarter
Some teams work around this by archiving HTML report artifacts in their CI system. But CI artifact retention is typically 30-90 days. After that, your test evidence evaporates.
No connection between automated and manual testing
Real-world QA is never 100% automated. Even teams with mature Playwright test automation still have manual test cases - exploratory testing, usability checks, edge cases that aren't worth automating.
Playwright knows nothing about these manual tests. So your automated test reporting lives in one system (CI artifacts, HTML reports) while manual test results live somewhere else (spreadsheets, Jira comments, Slack messages). There's no unified view.
When someone asks "what's the overall test coverage for this release?" you're stitching together data from three different sources - and hoping nothing falls through the cracks.
Screenshots without context
Yes, Playwright screenshots can capture failures. But a screenshot by itself is just a picture. It doesn't tell you:
- Which test case this screenshot belongs to
- What the expected behavior was
- Whether this is a regression or a known issue
- Who reviewed it and what they decided
No test case traceability
Playwright tests are code files organized however the developer chose to structure them. They have no formal relationship to requirements, user stories, or test plans.
This means you can't answer basic questions like:
- "Which requirements have automated test coverage?"
- "What test cases cover the payment module?"
- "Did we run regression tests for all critical paths before this release?"
These aren't exotic enterprise concerns. They're fundamental questions that any team shipping software to real users should be able to answer.
Reports don't aggregate across projects
Larger organizations don't have one Playwright project - they have dozens. Microservices, front-end apps, integration tests, each with their own test suites.
The Playwright HTML report shows results for one project at a time. There's no way to get a cross-project view of test health. Building that aggregation layer yourself means maintaining a custom reporting service - which is now a product you're building and supporting internally.
Enter Playwright CLI and the agent-driven test era
There's Playwright CLI - a command-line interface for driving Playwright's browser automation. An MCP-based approach streams accessibility trees and screenshot bytes back into the model's context; a CLI approach saves output to disk and lets the caller decide what to read. That architecture difference is what makes it practical for AI coding agents to drive browser testing over long sessions without blowing through their context window.
This is the big shift. AI agents in Claude Code, Cursor, Copilot, and similar tools can now:
- Write new Playwright tests end-to-end based on a feature spec
- Run them, inspect failures, iterate on the test code
- Take screenshots and save traces for debugging
- Open PRs with passing test suites attached
Ten parallel agents, ten ephemeral HTML reports. When you have a handful of engineers running Playwright in CI, evidence chaos is tractable. When you have a dozen agents running tests across feature branches, each producing its own HTML report that dies in CI artifacts 30 days later, nobody has any idea what was actually tested across the codebase last week.
Agents won't tag your test cases. The old playbook - "just have developers add [TC-123] to their test names and maintain a curated test case catalog" - doesn't survive contact with an agent that's writing 50 new tests a day. Agents aren't going to stop and ask you which test plan to create first. Whatever pattern you use has to work with zero human pre-setup or it doesn't work at all.
The agent loop has to stay closed. The whole point of autonomous agents is that they operate without blocking on humans. If your test reporting pipeline requires a QA lead to create a test plan before the agent can upload results, you've broken the loop. The agent fails, waits for approval, or silently skips the reporting step. None of those are acceptable.
This is why TestCollab's zero-setup CLI import isn't just a convenience feature - it's the only pattern that works in an agent-first testing world. Zero pre-setup. Zero test plan management. The agent runs tests, calls one command, and TestCollab catches up with whatever structure the agent produced.
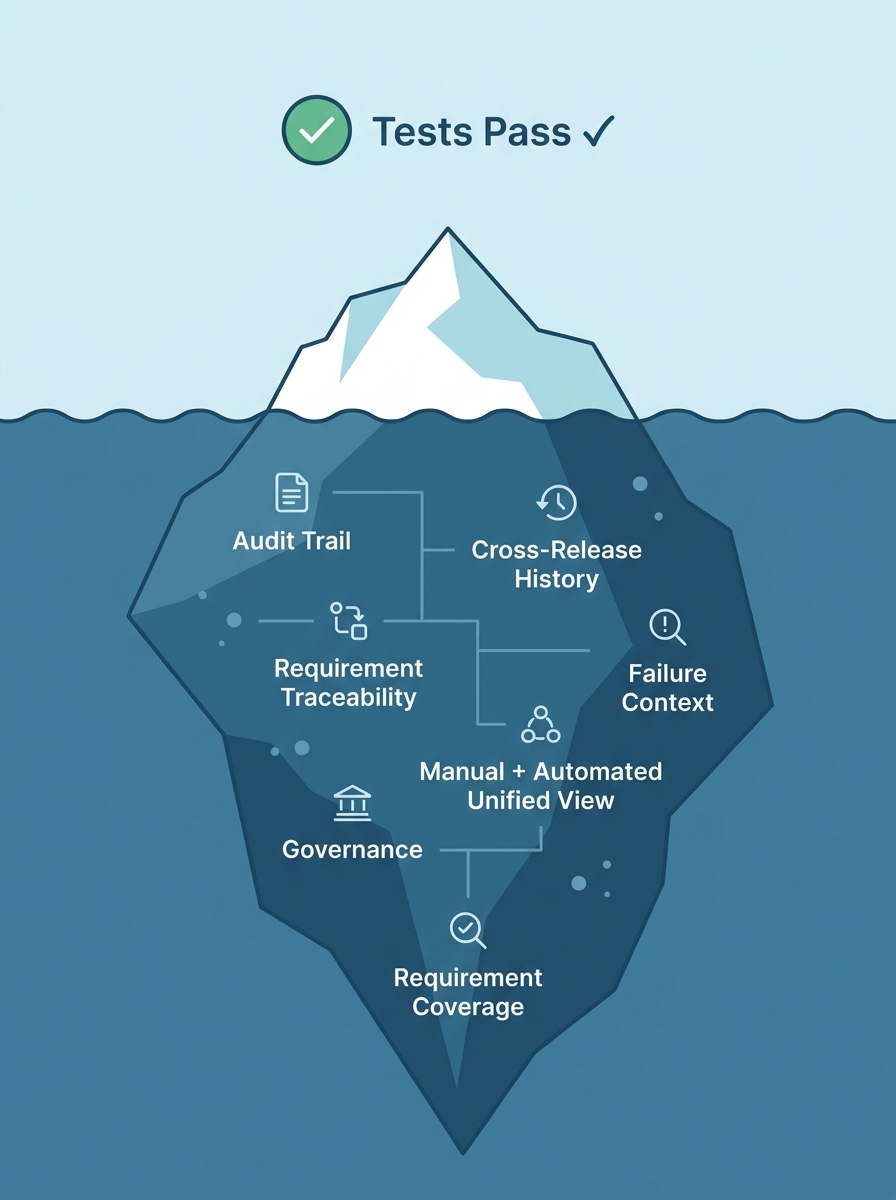
What teams actually need: test evidence that persists
The gap between "running automated tests" and "having a defensible test evidence strategy" is wider than most teams realize. Here's what closing that gap requires:
Persistent test results. Every test execution - automated or manual - stored permanently with full context. Not overwritten, not archived to cold storage after 30 days. Available instantly when needed.
Unified reporting. Automated test reporting from Playwright, Cypress, Selenium, and manual test results all in one place. One dashboard, one source of truth.
Evidence attachments. Screenshots, logs, videos, and any other artifacts attached directly to the test execution record. Not floating in CI artifacts - linked to the specific test case, test run, and release.
Traceability. Test cases mapped to requirements. Requirements mapped to test plans. Test plans mapped to releases. A complete chain from "what we built" to "how we proved it works."
Audit-ready exports. When compliance asks for proof, you click a button - not spend three days reconstructing history from CI logs.
How TestCollab fills the Playwright reporting gap
TestCollab is a test case management tool designed to work alongside automation frameworks like Playwright - not replace them. It fills the exact gaps that Playwright wasn't built to handle.
Zero-setup JUnit import via the TestCollab CLI
Playwright already generates JUnit XML natively. The TestCollab CLI (@testcollab/cli) reads that JUnit file and uploads results with a single command - no test plan to create, no test case IDs to manage, no config file to maintain.
Step 1: Add the JUnit reporter to your playwright.config.ts:
export default defineConfig({
reporter: [
['html'],
['junit', { outputFile: 'results.xml' }]
],
});Step 2: After Playwright finishes, one command uploads everything:
tc report \
--project 123 \
--format junit \
--result-file results.xml \
--auto-createThat's the entire integration. On the first run, the --auto-create flag parses your JUnit output and sets up everything in TestCollab for you:
- Creates a
CI Importedtag (reused on future runs) - Creates test suites from your Playwright file paths or class names, with humanized names
- Creates test cases from your test names, tagged and organized under the right suite
- Creates a
CIfolder for test plans - Creates a new test plan called
CI Run: DD-MM-YYYY HH:MM - Uploads the results - pass/fail/skip, timings, and failure stack traces
No pre-built test plan. No [TC-123] prefixes in your test names (though the CLI will honor them if you add them for stable cases). Your Playwright tests run exactly as they do today - the CLI just captures the evidence and mirrors your test structure into TestCollab automatically.
Failure context stays with the execution
When a Playwright test fails, the JUnit XML captures the failure message and stack trace. The TestCollab CLI pulls those straight onto the test case execution record as comments, so the debugging context lives alongside the run itself - not buried in a separate CI log file that expires in 30 days.
Three months later, when someone asks "what happened when the login test failed on the v2.4 release?" - you click through to the execution in TestCollab and see the failure reason, the test plan it ran under, who reviewed it, and what action was taken. TestCollab also supports file attachments on test executions, so teams that want richer evidence - videos, traces, custom artifacts - can attach them to the same record during triage.
Manual and automated tests in one place
TestCollab doesn't care whether a test was run by Playwright or by a human. Manual test executions sit right next to automated results. The release dashboard shows overall coverage - not just the slice that Playwright can see.
This is critical for teams practicing a mix of automated and exploratory testing. You get a single view of test health without maintaining parallel tracking systems.
Test case traceability from requirement to release
Every test case in TestCollab can be linked to requirements, grouped into test plans, and associated with releases. When you look at a release, you see:
- How many test cases are planned
- How many have been executed (automated + manual)
- Pass/fail rates across the entire scope
- Which requirements still lack test coverage
Cross-project dashboards and automated test reporting
TestCollab aggregates test results across all your projects. Whether you have three Playwright projects or thirty, the reporting layer gives you a unified view of test health across the organization.
Filter by project, release, environment, or time period. Drill down from the dashboard to individual test executions. Export reports for stakeholders who need data without logging into the tool.
TestCollab as a QA governance layer for AI agents
Agent-driven testing creates a new organizational problem: who is accountable for what the agent tested, and how do humans stay in the loop without becoming a bottleneck? This is where the framing shifts from "test management tool" to governance layer.
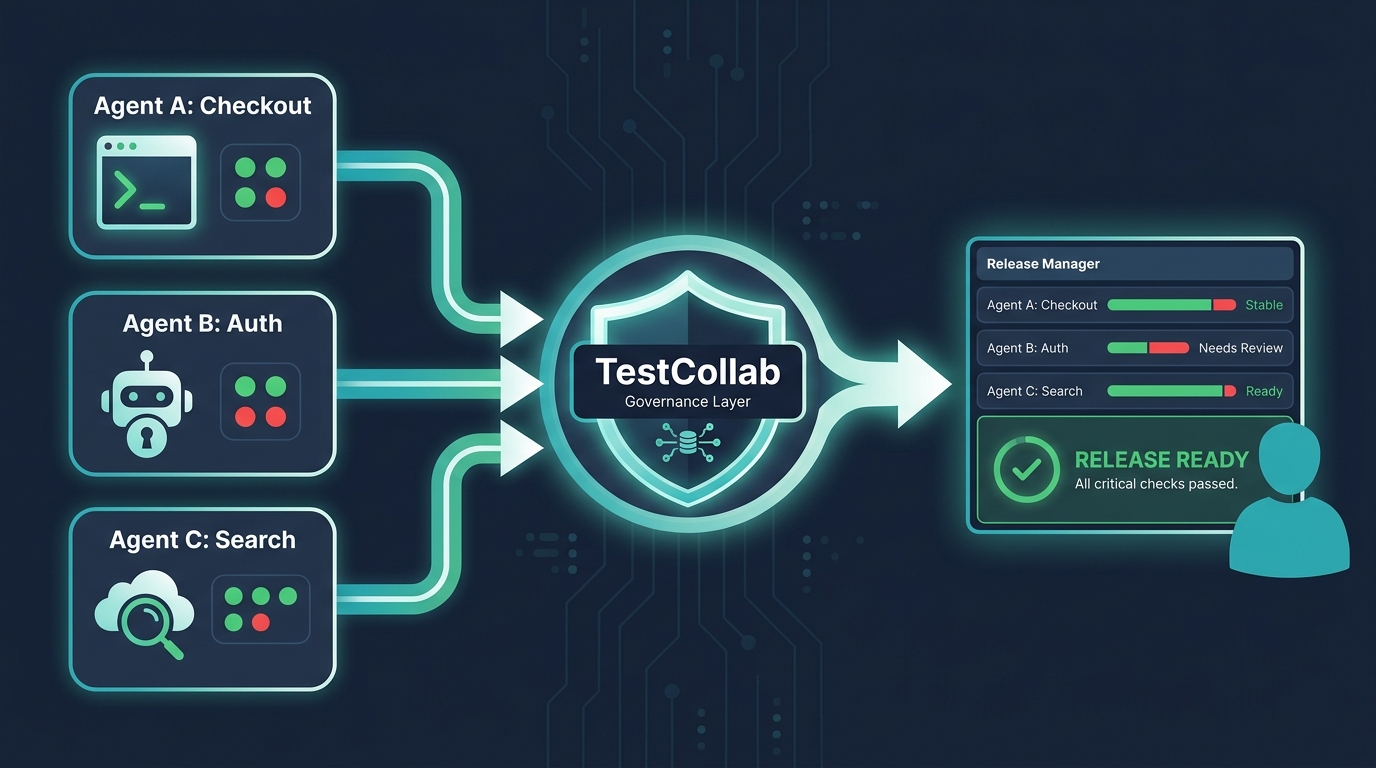
Here's what that looks like in practice.
A durable audit trail of agent activity. Every time an agent runs tc report --auto-create, TestCollab records a new test plan with a timestamp, the full set of test cases the agent executed, pass/fail status, and failure details. Six months from now, when someone asks "what did the checkout agent actually test on March 14?", the answer is a two-click drill-down - not an archaeology dig through dead CI artifacts.
Central reporting across every agent, every branch. When you have agents running tests on 5 branches across 3 services, they all report into the same TestCollab project. Humans see one dashboard with agent-generated results filtered by branch, release, or time window - not 28 CI artifact folders scattered across GitHub Actions and GitLab runners.
Human-in-the-loop review for agent-generated failures. The agent proposes; the human disposes. When a test fails, QA leads can triage the execution in TestCollab, mark it as a real regression, a flaky test, or a false positive from the agent's test generation. That judgment gets stored alongside the execution, so the next agent run has context to reason about. This is the review step that raw CI output makes impossible.
Accountability for what was missed. When a production bug slips through, the first question is always "did we test this?" With agent-driven testing, the question gets sharper: "did the agent test this, or did it skip it?" TestCollab's test case catalog plus execution history gives you a concrete answer. You can see which test cases exist, which ran, which passed, and which the agent never touched - per release.
Cross-agent correlation. If Agent A tested checkout and Agent B tested auth and Agent C tested search, a human release manager can see all three in a single view to assess overall readiness. No agent has the full picture on its own. The governance layer is where the pictures combine.
Policy enforcement hooks. Because TestCollab knows which test cases are tagged critical or mapped to regulated requirements, you can define rules like "a release is not ready until all critical test cases have a passing execution in the last 48 hours." Agents can run as much as they want, but the governance layer decides when a release is actually cleared to ship.
The net effect: agents get to operate at their native speed (no humans blocking the loop), while humans keep meaningful oversight (the governance layer catches drift, gaps, and sloppy test generation). TestCollab becomes the permanent record that both sides can trust.
The practical setup: Playwright + TestCollab
Here's the full GitHub Actions workflow. The same pattern works in GitLab CI, Jenkins, or Azure DevOps - it's two commands either way:
# .github/workflows/test.yml
- run: npm install -g @testcollab/cli && npm ci
- run: PLAYWRIGHT_JUNIT_OUTPUT_NAME=results.xml npx playwright test --reporter=junit
- name: Upload results to TestCollab
if: always()
run: |
tc report \
--project ${{ secrets.TC_PROJECT_ID }} \
--format junit \
--result-file results.xml \
--auto-create
env:
TESTCOLLAB_TOKEN: ${{ secrets.TESTCOLLAB_TOKEN }}The if: always() ensures results are uploaded even when tests fail - which is exactly when you need the evidence most.
That's the entire workflow. No step for creating a test plan. No config file mapping Playwright test names to TestCollab IDs. No onboarding day spent curating a test case catalog that mirrors your test files. The CLI reads what Playwright produced and reflects it into TestCollab automatically.
This matters even more when AI coding agents are writing the tests. A Claude Code or Cursor agent can now spin up a new Playwright suite end-to-end - write the tests, run them, report the results - without stopping to say "please create a test plan in TestCollab first." The agent loop stays closed.
Playwright stays in its lane - fast, reliable test execution. TestCollab stays in its lane - evidence capture, traceability, and reporting. The --auto-create flag is the one-command bridge between them.
When you'll wish you had this from the start
Teams that postpone test evidence management always hit the same triggers:
The audit. SOC 2, ISO 27001, HIPAA, FDA - whatever your industry's compliance framework, the auditor will ask for proof of testing. "We run Playwright in CI" is not an answer they accept.
The production incident. A critical bug reaches production. Leadership asks: "Was this tested? Show me." Without persistent evidence, the answer is "probably, but we can't prove it."
The team scaling event. When you go from 5 to 25 engineers, tribal knowledge stops working. New team members need to understand what's tested, what isn't, and where the gaps are. A collection of Playwright test files doesn't communicate that.
The customer escalation. An enterprise customer reports a bug and asks for your test documentation. They want to see test plans, execution history, and evidence of regression coverage. This is table stakes for enterprise software.
The agent sprawl. You rolled out AI coding agents for test generation. It worked. Now you have 10 agents running across 20 branches producing hundreds of test executions a day. Without a governance layer, you have no idea what's actually been tested versus what an agent merely claimed to test. Engineering leadership starts asking uncomfortable questions about whether the velocity gain is real.
In each case, retroactively building test evidence is orders of magnitude harder than capturing it from the start.
Conclusion
Playwright is a powerful tool for what it was designed to do: automate browser testing with speed and reliability. And as AI coding agents take on more of the test-writing and test-running workload, that speed only goes up.
But running tests is only half the equation. Capturing evidence, enforcing governance, and giving humans a durable record of what agents actually tested - that's the other half. And a testing framework was never built to solve it.
The teams that get this right don't choose between Playwright and a test management platform. They use both: Playwright (with or without agents) for execution, and TestCollab as the governance and evidence layer that makes agent-driven QA safe to scale.
Everything in this article applies equally to Cypress, Selenium, WebdriverIO, and every other major testing framework. They all produce ephemeral reports. They all lose evidence when CI artifacts expire. None of them connect automated results to manual testing, requirements, or release history. The missing piece in modern CI/CD isn't test execution - teams have solved that. It's evidence retention and tracking. That's what TestCollab solves.
If you're running Playwright today - or any testing framework - or planning to turn coding agents loose on your test suite tomorrow - start a free trial of TestCollab and see how a governance layer changes the way your team ships software.