QA agent guide
The Claude Code QA agent: close the QA loop - generate, curate, run
Claude Code is Anthropic's CLI coding agent. With TestCollab it does both jobs: it generates test cases from your code or specs, and once you curate them into a plan, it drives a real browser through every case and reports pass or fail results back to TestCollab.
TL;DR
- The Claude Code QA agent does two co-equal jobs: it generates test cases in TestCollab from your code or specs, and it executes a curated test plan in a real browser. A human curates in between.
- Generation runs through the TestCollab MCP server, which gives Claude Code 17 tools for test cases, suites, and plans. Connect it once and author cases in natural language.
- Execution is the second half: humans curate the plan,
tc getTestPlanexports it as JSON, Claude Code drives a real browser through every case, andtc reportuploads the results. - Install the
testcollab-qaskill once into~/.claude/skills/, then run Claude Code from your own app directory and prompt it in plain English with a plan ID, a project ID, a URL, and login credentials. - Claude Code uses
playwright-cli(an accessibility-tree approach) so the same test plan keeps passing through CSS changes and minor re-renders. Results land back in TestCollab as Passed, Failed, Skipped, or Unexecuted.
QA leads, SDETs, QA engineers, developers, and engineering managers who want an AI agent to both draft test cases and execute curated plans. This page covers the full loop with Claude Code. For the broader set of QA use cases (exploratory, risk analysis, and more), see the Claude Code for QA testing guide.
What is the Claude Code QA agent?
The Claude Code QA agent is Anthropic's command-line coding agent put to work on QA, and it has two co-equal capabilities. It can WRITE test cases, generating them from your code or specs straight into TestCollab, and it can RUN curated plans in a real browser through its built-in playwright-cli capability. A human curates in between: the agent drafts, your team refines and assembles a plan, then the same agent executes that plan. One agent covers both creating and running tests.
The word agent matters here, and it is easy to misread. When the agent executes, it is not an oracle that invents a test strategy. It does not look at your product and decide which flows are risky or which edge cases deserve coverage during a run. That judgment stays with your team. The execution job starts after the thinking is done: it takes the curated steps and expected results, opens a browser, and performs the clicking, typing, and verifying that a human tester would otherwise do by hand. Humans decide what to test. The agent decides how to click through it.
Generation is the other half. Here Claude Code reads your requirements, code, or user stories and proposes new test cases, suites, and plans for you to review. Both halves are real product workflows and both run through TestCollab, but they are distinct jobs joined by a human curation step. This guide covers both, in two parts. If you want Claude Code to run exploratory sessions or analyze risk from a recent merge, that is covered in the broader use-case guide linked at the end.
- Writes and runs
- The agent both generates test cases into TestCollab and executes the plans your team curates. Generation drafts coverage for review; execution runs exactly the cases your team approved, with the pass or fail criteria defined by humans.
- Terminal native
- Claude Code runs in your terminal alongside your dev tools. You launch it from your app's project directory and prompt it in natural language.
- Built-in browser automation
- Claude Code drives a real browser through
playwright-cli, an accessibility-tree approach. There is no separate browser agent to install. - Skill driven
- A small
testcollab-qaskill teaches Claude Code the full export-drive-report loop. You install it once and Claude Code loads it automatically when your prompt matches. - Reports back to TestCollab
- Results upload as JUnit XML with
[TC-ID]prefixes, so each result maps to the right test case and shows up as Passed, Failed, Skipped, or Unexecuted in your test plan.
With TestCollab: the curated plan lives in your test management tool, and the Claude Code QA agent both authors cases into it and clicks through it. You keep ownership of what to test and the agent handles the repetitive drafting and execution.
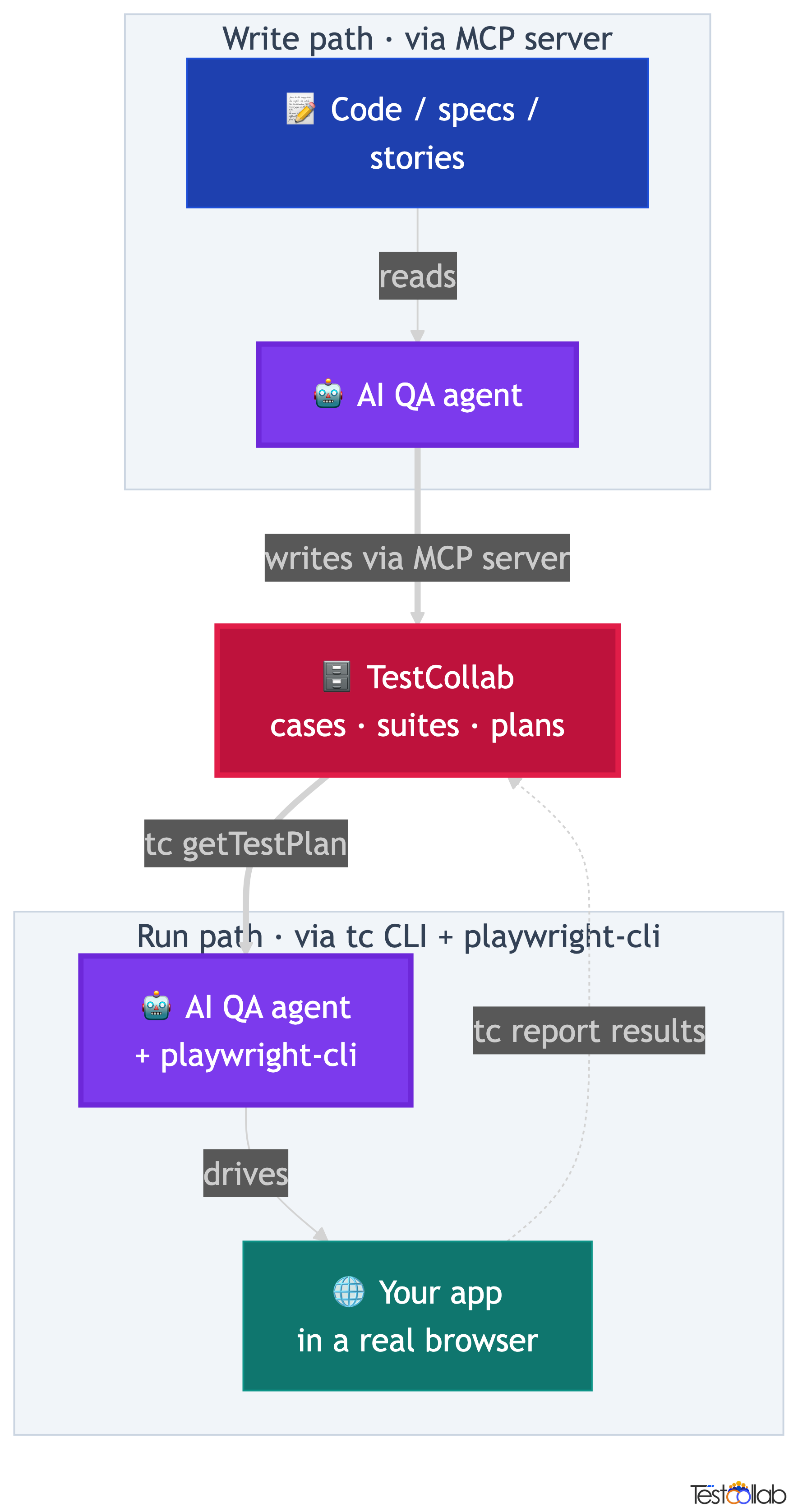
How Claude Code closes the QA loop: write, curate, run, report
The full cycle is a loop, and a human curation step sits at its center. The agent writes, a person curates, the same agent runs, and the results report back into TestCollab against the original cases. Once you understand the cycle, the rest of this guide is just the specific commands for each half.
First, Claude Code writes: it reads your code or specs and drafts test cases, suites, and plans into TestCollab through the MCP server. Second, humans curate: your team reviews the drafted cases, refines steps and expected results, and assembles a test plan. This is the part that requires product knowledge and cannot be automated away. Third, the same Claude Code agent runs: tc getTestPlan exports the curated plan as JSON, Claude Code opens a browser and executes each case, and tc report uploads the results back to TestCollab as JUnit XML.
The contract between TestCollab and the agent on the run side is just two CLI commands. tc getTestPlan hands the agent a plan, and tc report takes results back. Everything in between is the agent's job. That is why the run loop is agent-agnostic: Claude Code is one agent that fits the contract, but the same export-drive-report pattern works with Hermes Agent, Codex, or any agent that can drive a browser.
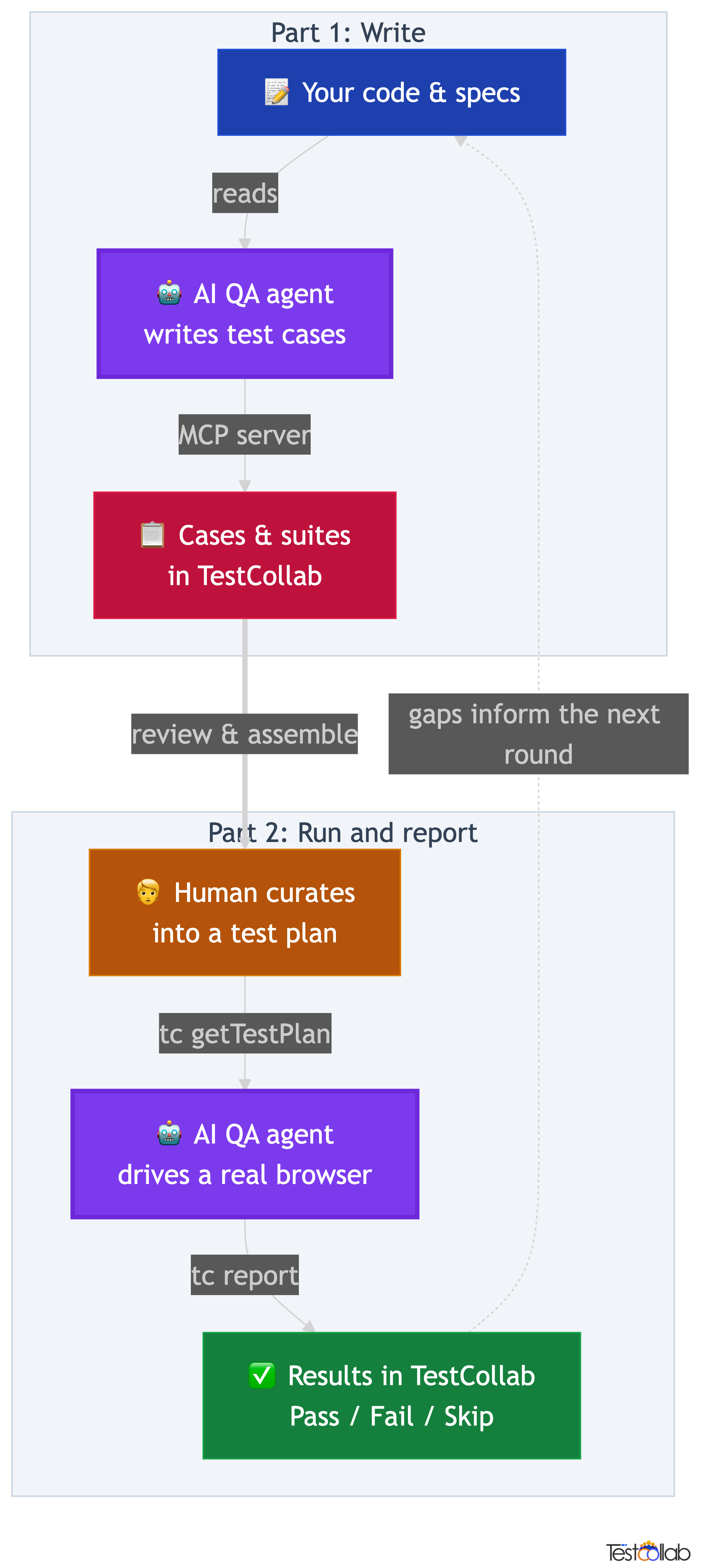
The full QA loop
- The agent writes the cases. Claude Code reads your code or specs and drafts test cases, suites, and plans into TestCollab through the MCP server.
- Humans curate the plan. Your team reviews the drafted cases, refines steps and expected results, and assembles a test plan with concrete pass or fail criteria.
- The same agent runs the plan.
tc getTestPlanexports the curated plan as JSON, and Claude Code opens a real browser and walks each case step by step. - Results report back. Claude Code generates JUnit XML with
[TC-ID]prefixes andtc reportpushes it back, so each result maps to the right test case in your plan.
With TestCollab: the plan and the results live in your test plan management the whole time. The agent drafts into it and clicks through it, but the curated plan and the result history stay in TestCollab where your team already works.
Generate test cases
Want Claude Code to read your code or specs and draft cases into TestCollab? Jump to Part 1 for the MCP server setup and the generation workflow.
Run and report
Already have a curated plan and just want to execute it? Jump to Part 2 for the tc CLI and QA skill setup and the run workflow.
Set up Claude Code for TestCollab
Both halves of the loop share the same base prerequisites. Get these in place once and you are ready to wire up either capability. The base setup is your TestCollab account and token, your project ID, and Claude Code itself installed and authenticated.
Shared prerequisites
- - Create a TestCollab account if you do not have one.
- - Generate an API token in TestCollab: Profile then API Token.
- - Note your project ID so you can target the right workspace.
- - Install and authenticate Claude Code itself from the Claude Code docs.
Each half of the loop needs one extra piece of setup on top of the shared prerequisites. For writing test cases, connect the TestCollab MCP server as described in Part 1. For running plans, install the tc CLI and the TestCollab QA skill as described in Part 2. Pick the half you need, or set up both to run the full loop.
Part 1: Write test cases with Claude Code
The first half of the loop is generation: Claude Code reads your code, specs, or user stories and creates structured test cases, suites, and even test plans directly in TestCollab. Generation runs through the TestCollab MCP server today, which exposes 17 tools for test cases, suites, and test plans over the Model Context Protocol. Connect it once and Claude Code can author cases in your workspace the same way it drives a browser: through natural language.
From code to cases
Point Claude Code at a feature or module. It reads the implementation, identifies happy paths, edge cases, and error handling, then creates test cases with steps and expected results, organized into suites.
From specs to scenarios
No code access needed for generation either. Give Claude Code a user story, requirement, or API spec and it drafts cases covering success paths, failure modes, and corner cases for you to review and keep.
Close the loop
Generate cases, curate them into a plan, then execute that plan with the same agent using the tc getTestPlan loop in Part 2. One agent covers both halves of QA.
Connect the MCP server so Claude Code can write cases
Generation runs through the TestCollab MCP server. Claude Code has native MCP support, so a single claude mcp add command registers the server and its tools become available in your next session. A write-only reader needs nothing from Part 2: connect the server, restart, and start prompting.
Connect the TestCollab MCP server
- Get your API token from TestCollab: Profile then API Token. Note your project ID as well.
- Register the TestCollab MCP server with Claude Code using the config below.
- Restart Claude Code so it discovers the server's tools.
- Prompt it in natural language, for example: "Generate test cases for the checkout module and add them to project 16."
Claude Code has native MCP support, so a single claude mcp add command registers the server and its tools become available in your next session.
claude mcp add testcollab \
-e TC_API_TOKEN=your-api-token \
-e TC_API_URL=https://api.testcollab.io \
-e TC_DEFAULT_PROJECT=your-project-id \
-- npx -y @testcollab/mcp-serverToday, test-case generation runs through the MCP server, while the tc CLI handles execution (tc getTestPlan and tc report). CLI-driven generation is coming soon, so you will be able to script case creation the same way you already script runs. Until then: MCP server for generating, CLI for executing.
Claude Code has native MCP support, so the TestCollab tools are discovered automatically after you register the server and restart your session. For the full range of generation workflows - from a single feature to bootstrapping coverage on an untested codebase - see the Claude Code for QA testing guide and our walkthrough of automated test case generation with Claude Code and MCP.
Generate test cases, suites, and plans with Claude Code
Once the MCP server is connected, generating cases is just natural language. You point Claude Code at a feature or hand it a spec and ask it to author coverage. Because Claude Code already reads your project, a code-aware prompt is enough: it inspects the implementation, identifies happy paths, edge cases, and error handling, then creates test cases with concrete steps and expected results.
Under the hood, the MCP server gives Claude Code 17 tools for test cases, suites, and test plans. So a single prompt can do more than create loose cases: it can group them into suites and assemble them into a draft test plan in the right project. You stay in plain English and the agent maps your intent onto those tools.
The output lands directly in your TestCollab workspace, in the project you named. From there it is ready for the curation step: a human reviews each drafted case, refines the steps and expected results, and decides what makes it into the plan. Generation drafts the raw material; the next section is where you turn that draft into something runnable.
Generate test cases for the checkout module and add them to project 16.With TestCollab: the cases Claude Code drafts land in the same project your team curates in, so generated coverage is reviewed and assembled into a plan in the same test management tool the run step later executes against.
Curate generated cases into a test plan
Curation is the human hinge between the two halves of the loop. It is what turns WRITE output into RUN input. Claude Code can draft a lot of cases quickly, but a draft is not a plan: someone with product knowledge has to decide what actually belongs in the run and make each case unambiguous enough for an agent to verify.
This step is fast but it is not optional. Review the AI-drafted cases, refine the steps and expected results so they are concrete, organize the keepers into suites, and assemble them into a test plan. While you are here, note the plan ID and the project ID, because Part 2 consumes them directly: the run prompt points at exactly that plan in exactly that project.
Turn drafts into a runnable plan
- - Review the AI-drafted cases. Read what Claude Code generated and drop anything off-target or duplicated.
- - Refine steps and expected results. Make each expected result concrete and verifiable so the agent has something unambiguous to check.
- - Organize into suites. Group the keepers into suites that reflect how you think about coverage.
- - Assemble a test plan. Pull the curated cases into a plan, then note the plan ID and project ID so Part 2 can target them.
Part 2: Run and report with Claude Code
The second half of the loop is execution: Claude Code takes a human-curated plan and drives a real browser through it, case by case, then reports what passed and what failed. This is the step that gives you repeatable, hands-off regression runs from a plan your team already trusts.
The contract between TestCollab and the agent is just two CLI commands. tc getTestPlan exports the curated plan as JSON, Claude Code opens a browser and walks each case, and tc report uploads the results back. Everything in between is the agent's job, which is why the same export-drive-report pattern works across agents. A run-only reader needs nothing from Part 1: install the tooling below, point the agent at a plan, and go.
The four-step QA agent loop
- Humans curate the plan. In TestCollab, your team decides what to test and writes the test cases with concrete steps and expected results.
tc getTestPlanexports it. The CLI pulls the curated plan out of TestCollab as structured JSON that Claude Code can read.- Claude Code drives the browser. It opens a real browser, walks each test case step by step, interacts with the page, and verifies each expected result.
tc reportuploads results. Claude Code generates JUnit XML with[TC-ID]prefixes and pushes it back, so each result maps to the right test case in your plan.
With TestCollab: because the loop is defined by tc getTestPlan and tc report, you can swap Claude Code for another agent without changing anything in your test plan management. The plan and the results live in TestCollab, the agent is interchangeable.
Install the tc CLI and QA skill so Claude Code can run plans
Execution setup has two pieces on top of the shared prerequisites: the TestCollab CLI and the TestCollab QA skill. Claude Code already includes browser automation through playwright-cli, so unlike some agents there is no separate browser tool to wire up. The first time a browser is needed, Claude Code will prompt you to install the playwright-cli browser if it is not already present.
The one piece that is genuinely one-time is the QA skill. You install it once into Claude Code's user-global skills directory, and from then on it is available in every project on your machine. A run-only reader needs nothing from Part 1: install the CLI, export your token, install the skill, and you are ready to run.
npm install -g @testcollab/cli
tc --versionexport TESTCOLLAB_TOKEN=your-token-hereWith the CLI and token in place, install the TestCollab QA skill with the one-liner below. It is the same install shape used by the other TestCollab QA agents, so if you have set up Hermes or Codex this will look familiar.
curl -fsSL https://raw.githubusercontent.com/TCSoftInc/testcollab-cli/main/claude-code-skill/testcollab-qa/scripts/install.sh | bashls ~/.claude/skills/testcollab-qa/The script drops SKILL.md into ~/.claude/skills/testcollab-qa/, which is user-global: the skill is available in every project on your machine. It also checks that Claude Code and @testcollab/cli are installed and warns if TESTCOLLAB_TOKEN is unset. If you would rather scope the skill to a single repo, drop the same SKILL.md into your-app/.claude/skills/testcollab-qa/SKILL.md instead. Same skill, narrower visibility.
With TestCollab: Claude Code already includes browser automation through playwright-cli, so there is no separate browser tool to install for execution. The first time a browser is needed, Claude Code prompts you to install the playwright-cli browser if it is not already present.
Run a test plan with Claude Code
This is the step people most often get wrong, so it is worth saying plainly: you run Claude Code from your own application's directory, not from testcollab-cli. The QA skill is loaded from your user-global skills directory no matter where you are, and the agent needs to be in the context of the app you are actually testing. Treat it exactly like the directory you would cd into to run tests by hand.
Once you are in your app directory and Claude Code is running, you prompt it in natural language. Give it the test plan ID, the project ID, the URL to test against, and the login credentials. There is no special syntax. Claude Code matches your prompt to the testcollab-qa skill through the skill's description and takes over from there.
cd ~/your-app
claudeExecute test plan 555 in project 16 against http://localhost:3000.
Login: testuser@example.com / password123.What Claude Code does after the prompt
- Runs
tc getTestPlanto fetch the curated plan as JSON. - Opens a Chromium browser through
playwright-cli. - Navigates to each page, interacts with elements, and verifies each expected result.
- Generates a JUnit XML result file with
[TC-ID]prefixes so results map to your test cases. - Uploads the results with
tc report. - Prints a summary of pass, fail, and skip counts in the terminal.
For CI or scripted runs where you cannot sit in an interactive session, Claude Code takes the same prompt non-interactively with the -p flag. Point it at a staging URL rather than localhost so it runs against a deployed environment.
claude -p "Execute test plan 555 in project 16 against http://staging.example.com. \
Login: testuser@example.com / password123."With TestCollab: the plan ID and project ID in your prompt point straight at a plan in your TestCollab workspace, so the agent always executes exactly the cases your team curated and nothing it invented on its own.
How Claude Code drives a real browser
Claude Code drives the browser through playwright-cli, which works from the page's accessibility tree rather than from screenshots or brittle CSS selectors. The accessibility tree is a text representation of what is actually on the page: headings, buttons, inputs, and their labels, each with a reference ID for interactive elements.
This matters for stability. Hand-written end-to-end suites tend to break the moment a class name changes or a component re-renders, because they are pinned to selectors that describe the markup rather than the meaning. An accessibility-tree approach targets the Save button because it is the button labeled Save, not because it has a particular CSS class. The result is that the same curated test plan keeps passing through CSS refactors, design tweaks, and minor re-renders that would shatter a selector-based script.
For each step in a test case, Claude Code snapshots the page, finds the element it needs by its accessible role and label, performs the action, then snapshots again to verify the expected result. If the expected text or state is not present in the accessibility tree, the case is marked failed with a note describing what was expected versus what was actually found.
| Test step | What the agent does |
|---|---|
| "Navigate to /settings" | Navigates the browser to the full URL. |
| "Click the Save button" | Snapshots the page, finds the Save button by its label, and clicks it by reference ID. |
| "Enter 'admin@example.com' in the email field" | Snapshots the page, locates the email input by its accessible label, and fills it with the value. |
| "Verify the success message appears" | Snapshots the page and checks the accessibility tree for the expected text. |
| "The page title should be 'Dashboard'" | Snapshots and verifies the heading element contains "Dashboard". |
With TestCollab: because verification reads the accessibility tree, the concrete expected results you write in your TestCollab test cases are exactly what the agent checks against. Specific expected results give the agent something unambiguous to verify.
Results back in TestCollab
When Claude Code finishes a plan, it writes a JUnit XML file and uploads it with tc report. The mechanism that ties each result back to the correct test case is the [TC-ID] convention: every <testcase> name is prefixed with the TestCollab test case ID in square brackets, like [TC-42].
That prefix is load-bearing. tc report reads the [TC-42] to match the result to test case 42 in your plan and update its execution status. Without the prefix, the report would create brand new test cases instead of updating the ones you curated, which is exactly what you do not want. The QA skill generates the prefixes for you, so in normal use this just works, but it is worth knowing why the format looks the way it does.
A failed case carries a <failure> element with the message and a short expected-versus-actual description, so when you open the result in TestCollab you can see what the agent was looking for and what it found instead.
<testsuites>
<testsuite name="Sprint 12 Regression" tests="3" failures="1">
<testcase classname="Login" name="[TC-42] Valid login redirects to dashboard" time="4.2"/>
<testcase classname="Login" name="[TC-43] Invalid password shows error" time="3.1">
<failure message="Error message not found">
Expected: Error banner visible after wrong password.
Actual: Page reloaded without error indication.
</failure>
</testcase>
<testcase classname="Settings" name="[TC-44] User can update email" time="5.8"/>
</testsuite>
</testsuites>After tc report uploads the XML, results appear in the test plan's Test Cases tab with a color-coded status: Passed in green, Failed in red, Skipped in yellow, and Unexecuted in grey. Click any test case to see the full execution detail, including the failure message with expected versus actual results.
- Passed
- The agent verified every expected result for the case. Shown in green.
- Failed
- An expected result did not match what the agent found. The case carries a failure message with expected versus actual. Shown in red.
- Skipped
- The agent could not run the case, for example because a precondition was not met. Shown in yellow.
- Unexecuted
- A case in the plan that the run did not reach. Shown in grey.
With TestCollab: the TestCollab CLI handles both the export and the report, so the results from a Claude Code run sit in the same plan dashboards your team already uses for manual and automated runs.
Tips for better results with Claude Code
The quality of a run depends far more on the test plan than on the agent, and the same habits that make runs reliable also make generated cases better. Some of these tips help WRITING and some help RUNNING, so they are flagged below. The throughline is the same: concrete, specific cases beat vague ones whether Claude Code is drafting them or executing them.
- Write concrete expected results (helps WRITING and RUNNING). Specific expected results give the agent something unambiguous to check during a run, and they also make generated cases sharper. "URL is /dashboard and a table with at least 3 rows is visible" is verifiable. "The page loads correctly" is not.
- Keep plans small (RUNNING). 10 to 30 test cases per plan works best. Larger plans risk context drift, where the agent loses track around case 40. Split big suites into multiple plans.
- Provide credentials in the prompt (RUNNING). Tell Claude Code the login URL, email, and password upfront. Do not make it guess.
- Use staging, not production (RUNNING). The agent interacts with your app like a real user: it submits forms, creates records, and modifies data. Point it at a local or staging environment.
- Review failures manually (RUNNING). Agents sometimes misclassify a slow page load as a failure or miss a subtle UI state. Treat results as a first pass and review failures with human eyes before filing bugs.
Because Claude Code drives a real browser, it can genuinely submit forms and change data. Never point it at a production environment with live customer data. Use a local or staging instance so a misbehaving test case cannot cause real damage.
Claude Code vs other QA agents
Claude Code is one of three agents TestCollab documents for the QA loop, alongside Hermes Agent and Codex. All three support BOTH halves of the loop: they can generate test cases through the MCP server and run curated plans through the tc getTestPlan to browser to tc report contract. The plan and the results are identical regardless of which one you pick. The differences are in browser automation, where the skill installs, and which models drive the agent.
Claude Code's distinguishing trait is that browser automation is built in through playwright-cli with no extra configuration, and it fits naturally into a developer's existing flow: a developer already running Claude Code while coding can generate cases or execute a QA plan in the same session. Hermes is open source and brings model flexibility through OpenRouter. Codex sits inside an OpenAI-powered workflow but needs --full-auto so its sandbox lets the browser launch.
| Capability | Hermes Agent | Claude Code | Codex |
|---|---|---|---|
| Generate and run | Both (MCP + CLI) | Both (MCP + CLI) | Both (MCP + CLI) |
| Browser automation | Built-in (MCP) | Built-in (playwright-cli) | Via playwright-cli (needs --full-auto) |
| Skill install location | ~/.hermes/skills/software-development/testcollab-qa/ | ~/.claude/skills/testcollab-qa/ | ~/.codex/skills/testcollab-qa/ |
| Invocation | Natural-language prompt | Natural-language prompt | Natural-language prompt |
| Non-interactive command | hermes -z "..." | claude -p "..." | codex exec "..." |
| LLM flexibility | 200+ models via OpenRouter | Claude models | OpenAI models |
| Best for | Dedicated QA agent runs | Developer-driven QA during coding | Repo-aware QA in an OpenAI workflow |
If you want to compare the other two, see the Hermes QA agent guide and the Codex QA agent guide. For the full hands-on tutorial that walks through all three agents end to end, read how QA agents run your test plans.
Glossary
- QA loop
- The full write-curate-run-report cycle: Claude Code generates test cases into TestCollab, a human curates them into a plan, the same agent runs the plan in a browser, and results report back against the original cases.
- QA agent
- An AI agent that both drafts test cases and executes a human-curated test plan against a running application via a real browser, reporting the results. During a run it does not decide what to test, it executes what the test cases describe.
- TestCollab MCP server
- The server that exposes TestCollab over the Model Context Protocol, giving Claude Code 17 tools to create test cases, suites, and plans in your workspace from code, specs, or user stories. It powers the generation half of the loop.
- TestCollab CLI
- The
tccommand-line tool that connects TestCollab to any QA agent for execution.tc getTestPlanexports a plan as JSON andtc reportuploads JUnit XML results back. - playwright-cli / accessibility tree
- Claude Code's built-in browser automation. It works from the page's accessibility tree (a text representation of roles and labels) rather than CSS selectors, which keeps test cases stable through UI changes.
- MCP (Model Context Protocol)
- An open protocol that lets AI agents connect to external tools and services. TestCollab's MCP server uses it to power AI test-case generation, which is the write half of the loop.
- JUnit XML / [TC-ID]
- The result format the agent produces. Each
<testcase>name is prefixed with the TestCollab test case ID in square brackets (like[TC-42]) sotc reportmaps each result to the correct case instead of creating new ones. - Skill
- A small instruction file (
SKILL.md) that teaches Claude Code the full export-drive-report loop. Thetestcollab-qaskill installs into~/.claude/skills/and loads automatically when your prompt matches its description.
Further Reading
FAQ
What is the Claude Code QA agent?
It is Claude Code, Anthropic's CLI coding agent, working on QA in two ways. It can generate test cases into TestCollab through the MCP server, and with the TestCollab QA skill it can execute a curated test plan: you give it a plan ID, a project ID, a URL, and login credentials, and it drives a real browser through every test case and reports pass or fail results back to TestCollab. The key point is that during a run it executes a plan your team curated: it does not decide what to test on its own.
Can Claude Code generate test cases, or only execute them?
Both. Generation and execution are two halves of the same loop. Generation uses the TestCollab MCP server, which gives Claude Code 17 tools to create test cases, suites, and plans directly in your workspace from code, specs, or user stories. Execution uses the tc CLI (tc getTestPlan then tc report). CLI-based generation is on the roadmap; today, connect the MCP server for generation.
Does the agent decide what to test?
Not during a run. Deciding what to test, writing the steps, and defining the expected results is human work done in TestCollab. The execution job starts after that: it takes the curated test cases and performs the clicking, typing, and verifying. Generation is separate: there Claude Code proposes new cases for you to review and curate. The curation step in between is what keeps a human in control of what makes it into a plan.
Do I need to install a separate browser tool for Claude Code?
No. Claude Code has browser automation built in through playwright-cli, the same accessibility-tree approach other TestCollab QA agents use. The first time a browser is needed, Claude Code prompts you to install the playwright-cli browser if it is not already present. There is no separate browser agent or MCP server to wire up for QA execution.
Where does the TestCollab QA skill install?
The install script drops SKILL.md into ~/.claude/skills/testcollab-qa/, which is user-global, so the skill works in every project on your machine. Verify with ls ~/.claude/skills/testcollab-qa/. If you prefer to scope it to a single repo, drop the same SKILL.md into your-app/.claude/skills/testcollab-qa/SKILL.md instead.
Which directory do I run Claude Code from?
Run it from your own application's project directory, the same place you would cd into to run tests by hand. Do not run it from testcollab-cli. The QA skill loads from your user-global skills directory regardless of where you are, and the agent needs the context of the app it is testing. So the pattern is cd ~/your-app and then claude.
Can I run Claude Code QA in CI?
Yes. Use the non-interactive -p flag and pass the same natural-language prompt inline, for example claude -p "Execute test plan 555 in project 16 against http://staging.example.com. Login: ...". Point it at a deployed staging URL rather than localhost, and make sure TESTCOLLAB_TOKEN is set in the CI environment so the skill can call the TestCollab API.
How do results map back to my test cases?
Through the [TC-ID] convention in the JUnit XML the agent generates. Each test case name is prefixed with its TestCollab ID in square brackets, like [TC-42]. tc report reads that prefix to update the matching case in your plan. Without it, the report would create new test cases instead of updating your curated ones. Results show as Passed, Failed, Skipped, or Unexecuted in the test plan's Test Cases tab.
Close the QA loop with Claude Code
Let Claude Code generate the cases, curate them into a plan, then let the same agent drive the browser through that plan while results flow back to TestCollab automatically.



