You type a prompt into your AI coding agent. "Build me a user authentication system with email and password." Code appears. It looks reasonable. You run it, and something works, but not quite the way you imagined. So you refine the prompt. More code appears. You go back and forth five, ten, fifteen times until you either get what you wanted or settle for what you got.
This is vibe coding. And for millions of developers, it's the default way to work with AI. But there's a growing realization in the developer community that vibe coding, while great for quick experiments, falls apart when you need predictable, maintainable software.
There's a more structured approach gaining momentum. It's called spec-driven development, and it puts specifications before code instead of letting the AI decide what to build.
What is vibe coding?
The term was coined by Andrej Karpathy in February 2025 to describe a style of AI-assisted programming where you surrender to the vibes. You describe what you want in natural language, the AI generates code, and you iterate through conversation until the result feels right.
The workflow looks like this: you write a prompt, the model generates code based on what it thinks you want, you review the output, edit your prompt, and repeat. Eventually, after a few rounds, you land on something that works.
Vibe coding works well for certain things. Prototyping a UI concept in minutes. Scaffolding a quick script to process some data. Learning how a library works by asking the AI to build something with it. Exploring ideas without committing to architecture.
But the limitations show up fast.
Where vibe coding breaks down
The fundamental issue with vibe coding is ambiguity. When you tell an AI "build me a login page," it has to make dozens of decisions you never specified. Which authentication library? Session-based or token-based? Where do error messages appear? What happens on rate limiting? How are passwords validated?
The AI fills in those blanks on its own. And it fills them differently every time. Run the same prompt ten times, and you might get ten different implementations. This is fine when you're exploring, but it's a problem when you need a specific outcome.
Beyond unpredictability, vibe coding skips the traditional software development lifecycle almost entirely. There's no planning phase, no requirements document, no design review. Decisions live in a chat thread, not in documentation. When a new team member joins, there's no spec to read - just a trail of prompts and iterations.
Testing becomes an afterthought. You build first, then figure out what to test. And because the AI made architectural decisions you never explicitly approved, you're testing an implementation you don't fully understand.
Technical debt accumulates invisibly. The AI chose a pattern in iteration three, built on top of it in iteration seven, and by iteration twelve, you have a codebase shaped by a series of conversational pivots rather than deliberate design.
What is spec-driven development?
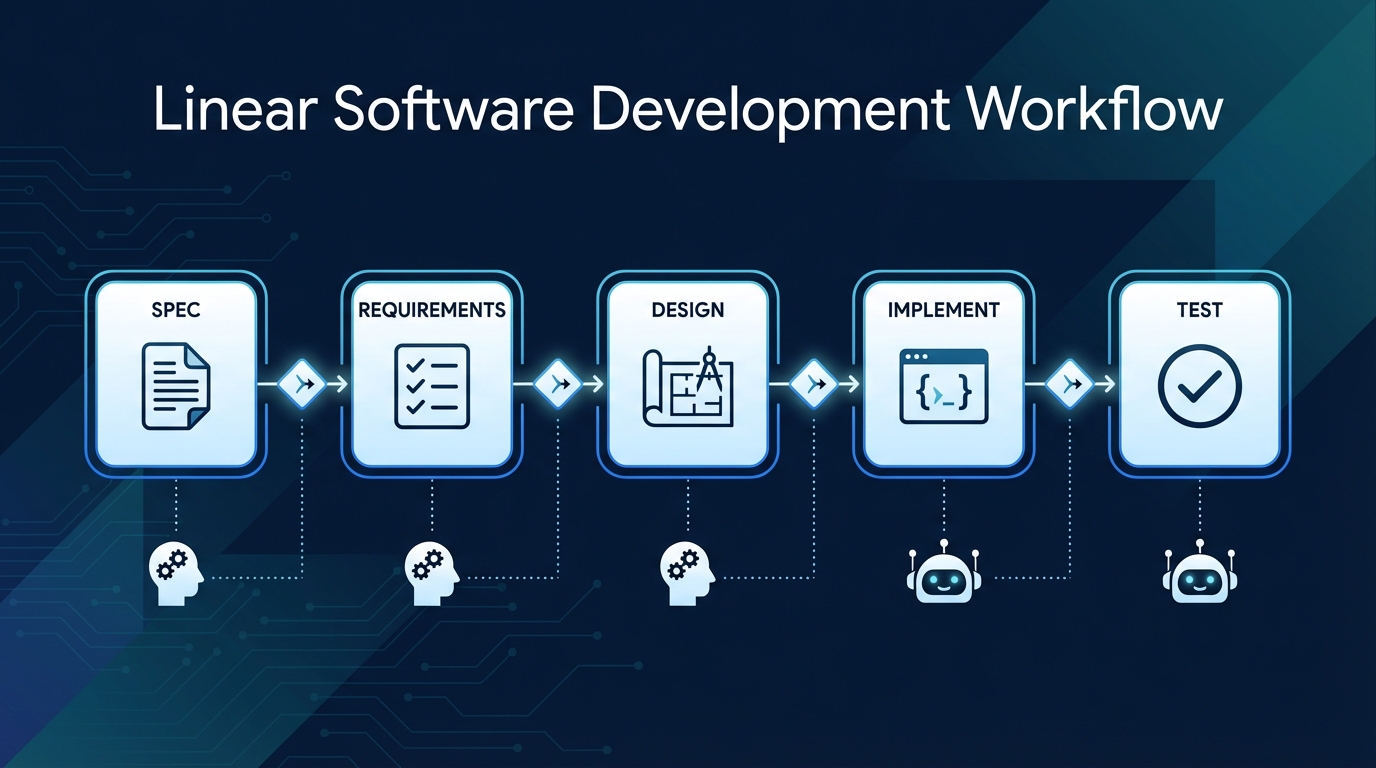
Spec-driven development takes the opposite approach. Instead of prompting the AI with what you want it to build, you first describe what the system should do - the behavior, the constraints, the inputs, the outputs, the error cases. This specification becomes a contract that drives everything downstream.
The workflow looks fundamentally different:
Step 1: Write the specification. Before any code exists, you describe the feature's behavior. Not implementation details, but what the system should do from the outside. For a payment webhook, this means: it accepts POST requests at /webhooks/stripe, validates the signature header, processes checkout.session.completed events, updates the order status in the database, and returns a 200 acknowledgment within 5 seconds.
Step 2: Generate requirements. Hand the spec to your AI agent and ask it to produce a structured requirements document. Review it. Does it capture everything? Did it infer reasonable defaults for things you didn't specify? Approve or refine.
Step 3: Create a design document. The AI turns approved requirements into implementation tasks with specific to-dos for code, tests, and documentation. You review the design before a single line of code is written.
Step 4: Implement. Now the AI writes code. But instead of improvising from a vague prompt, it's following a spec. The retry strategy, the idempotency handling, the timeout behavior - these were all decided in the spec, not left to the model's imagination.
Step 5: Generate and run tests. Here's where it gets powerful. Because the spec defines inputs, outputs, and edge cases explicitly, test cases generate themselves. Valid signature returns 200. Missing header returns 401. Duplicate event ID is safely ignored. The spec is the test contract.
The key insight is simple: AI models are excellent at following detailed instructions, but poor at inferring what you want from vague ones. Spec-driven development gives them better instructions.
A concrete example: vibe coding vs spec coding
The vibe coding approach:
"Build me a Stripe webhook handler. Use Node.js. It should process payments and update orders."
The AI produces something. Maybe it verifies signatures, maybe it doesn't. Maybe it handles duplicate events, maybe it processes them twice. Maybe it responds before processing, maybe it blocks until the database write completes. You don't know until you read the output, and by then the decisions are already baked in.
The spec-driven approach:
Feature: Stripe Webhook Handler
Endpoint: POST /webhooks/stripe
Headers: { stripe-signature: string }
Validates: HMAC-SHA256 signature using STRIPE_WEBHOOK_SECRET
Events handled:
checkout.session.completed → set order status to "paid"
charge.refunded → set order status to "refunded"
All other events → acknowledge with 200, no action
Constraints:
- Idempotent: store processed event IDs, skip duplicates
- Respond with 200 before async processing (Stripe retries on timeout)
- Log all events to webhook_events table
- Retry failed DB writes 3 times with exponential backoff
Error responses:
- Invalid signature → 401 { error: "INVALID_SIGNATURE" }
- Unknown event type → 200 (acknowledge silently)
- DB write failure after retries → 500, alert ops channelWhen the AI implements this, there's no ambiguity. Every decision is made. Every edge case is defined. The implementation matches the spec, and the tests verify the spec. If something doesn't work, you know whether it's a spec problem or an implementation problem.
How spec-driven development connects to TDD and BDD
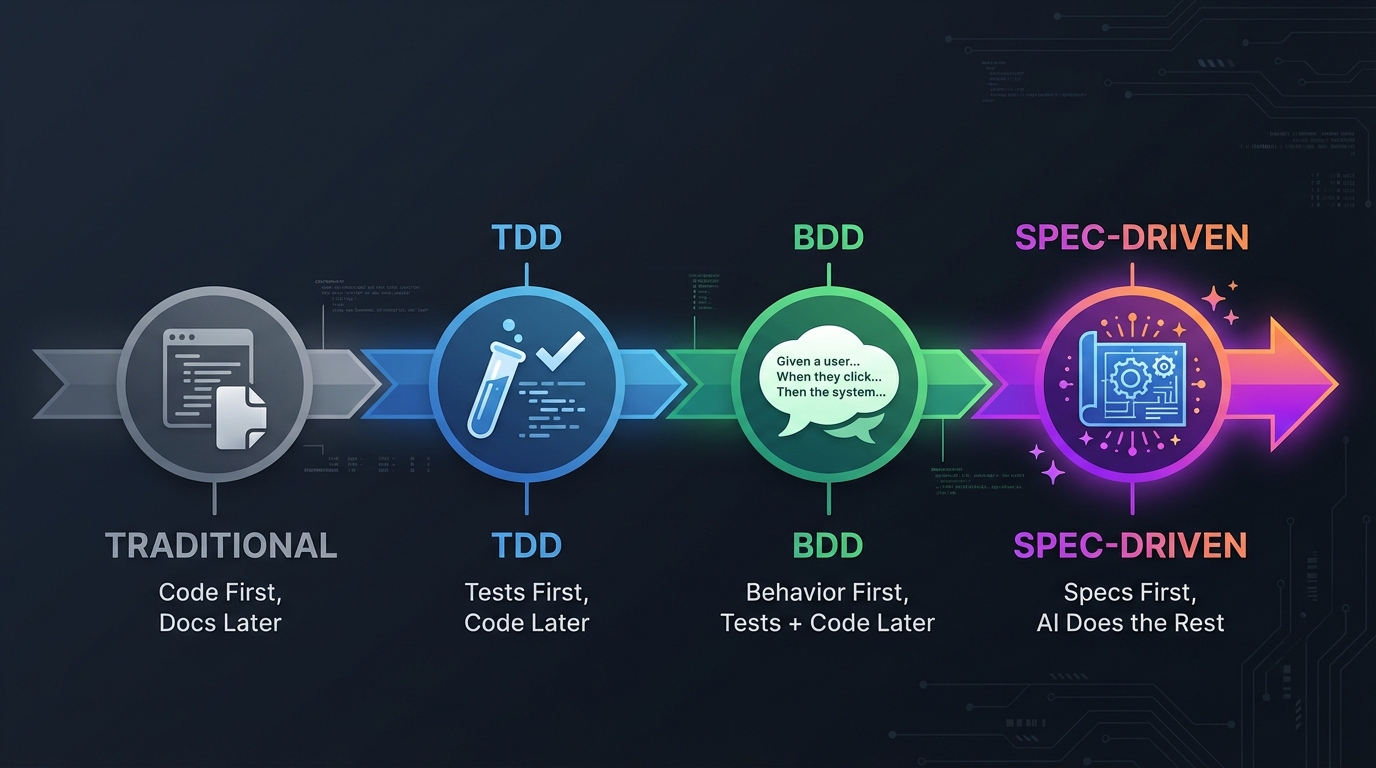
If this reminds you of test-driven development or behavior-driven development, you're right. Spec-driven development extends both TDD and BDD by adding AI to handle the implementation, turning your specification into the primary artifact that drives all downstream work.
In traditional development, the flow was: write code first, document later. Your intuition drives the architecture, and documentation catches up eventually (or never).
Test-driven development flipped part of this: write tests first, then write code to make them pass. The tests define expected behavior before implementation begins.
Behavior-driven development took it further by expressing those tests in natural language (Gherkin syntax) that non-developers can read and validate. A product manager can review a .feature file and confirm "yes, that's what the webhook should do" before any code exists.
Spec-driven development extends this chain: specifications first, then design, then code, then tests. The spec is the single source of truth, and AI handles the downstream work of turning specs into implementations and tests.
The practical challenge, of course, is keeping specs, code, and test results in sync across teams - especially when developers work in Git and QA works in a test management tool. If your team practices BDD, you can write Gherkin .feature files in your Git repo and sync them directly into your test management workflow. TestCollab's BDD sync keeps your feature files in Git as the source of truth while QA teams execute and track results from the web interface:
tc sync --project 42Run that in your CI pipeline, and your specs, scenarios, and test cases stay in lockstep. Developers define behavior in code, QA validates it in the tool, and nobody maintains a separate spreadsheet.
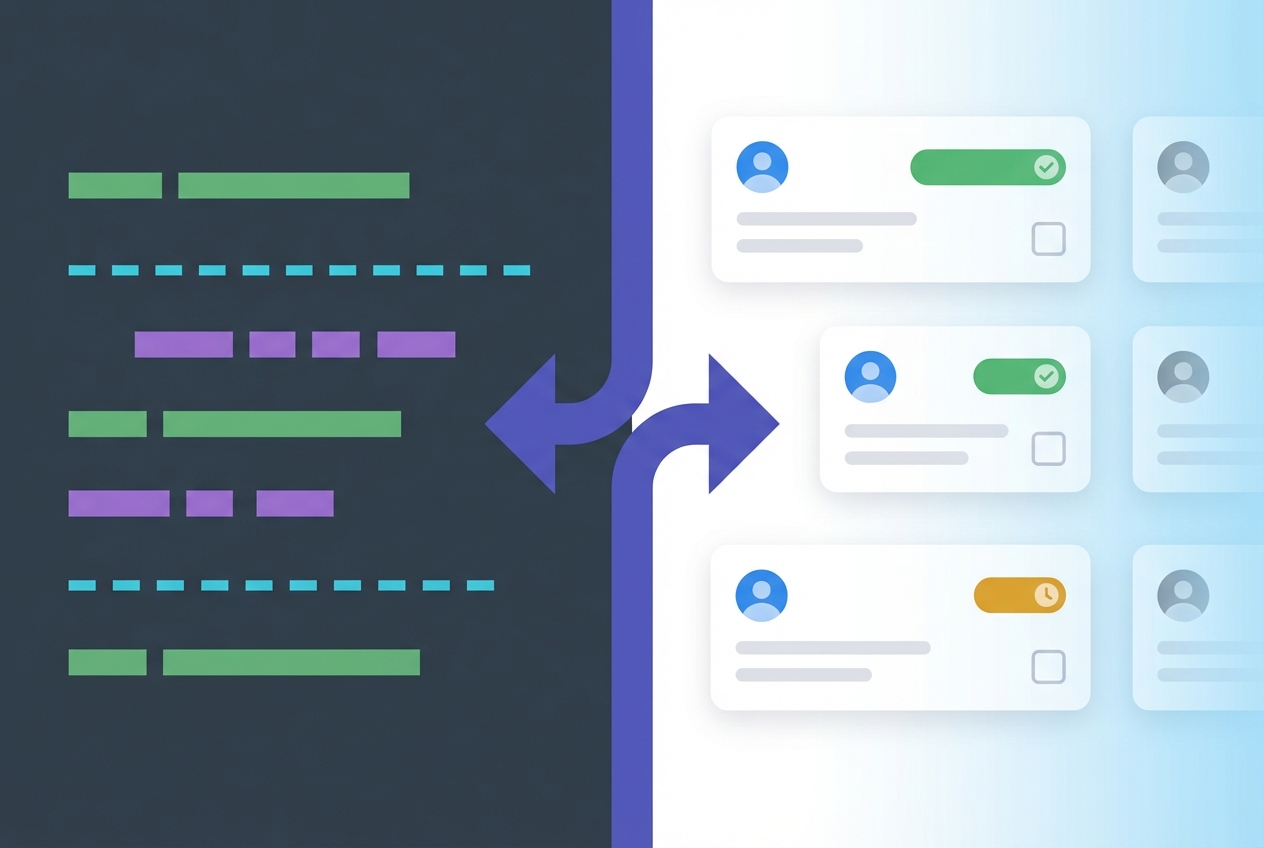
This is the full circle: specs drive implementation, implementation is verified by tests derived from those same specs, and the entire chain is traceable from requirement to test result.
Tools for spec-driven development
The spec-driven approach is tool-agnostic - it's a workflow pattern, not a product feature. But several tools make it easier:
GitHub Spec Kit is an open-source framework specifically built for spec-driven development with AI. It provides templates for writing specs and works with AI coding agents like Claude Code, Cursor, and GitHub Copilot to generate implementations from them.
Claude Code with CLAUDE.md files lets you define project conventions, architectural decisions, and specifications in markdown files that Claude reads before generating code. The CLAUDE.md file acts as a persistent spec that shapes every interaction.
Cursor Rules serve a similar purpose - .cursorrules files define how the AI should approach your project, what patterns to follow, and what constraints to respect.
PRD-driven workflows in tools like GitHub's Copilot coding agent start from a product requirements document and generate implementation plans before writing code.
The common pattern across all of these: give the AI structured context before asking it to code.
When to vibe code vs when to spec code
These aren't competing philosophies. They're different tools for different situations.
Vibe code when:
- You're prototyping or exploring an idea
- The project is a one-off script or throwaway experiment
- You're learning a new framework or library
- Speed matters more than predictability
- You're the only person who'll ever touch the code
Spec code when:
- The project will be maintained by a team
- You need predictable, reproducible implementations
- Testing and QA are part of the process
- The feature has defined requirements or edge cases
- You're building something that needs to work the same way every time
Many developers find the sweet spot is starting with vibe coding to explore and prototype, then switching to spec-driven development once the idea solidifies and needs to be built properly.
Getting started with your first spec-driven project
You don't need new tools to try this. Pick a feature you're about to build and spend twenty minutes writing a spec before opening your AI agent.
A basic spec should cover:
- What the feature does (one paragraph)
- Inputs it accepts (data types, validation rules)
- Outputs it produces (success and error responses)
- Constraints it operates under (performance, security, business rules)
- Edge cases it must handle (what happens when things go wrong)
The shift from vibe coding to spec-driven development isn't about giving up speed. It's about spending time in the right place. Twenty minutes on a spec saves two hours of prompt iteration and produces code you can actually trust.
And in a world where AI can write code faster than any human, the person who writes the best spec wins. If your team practices BDD or wants to keep specs and test execution in sync, see how TestCollab's BDD sync works.