Your team cannot test everything. Every release comes with a deadline, and every deadline forces a choice: which tests do you run, and which do you skip?
Most teams make this decision based on gut feeling. The senior tester knows which areas are fragile. The developer warns you about a tricky refactor. You run the tests that failed last time and hope for the best.
Risk-based testing replaces gut feeling with a framework. And with AI now capable of analyzing your codebase, defect history, and code changes, that framework is becoming dramatically more powerful.
This guide covers how risk-based testing works, where the traditional approach falls short, and how AI is changing the way teams decide what to test.
What Is Risk-Based Testing?
Risk-based testing is a prioritization strategy. Instead of treating every test case as equally important, you assign each one a risk score and focus your execution time on the tests that matter most.
The core formula is simple:
Risk = Likelihood of Failure x Business Impact
A payment processing module that breaks frequently has high likelihood and high impact - it gets tested first. A tooltip on an internal admin page that has never broken has low likelihood and low impact - it can wait.
This sounds obvious when you write it down. But in practice, teams with 500+ test cases and a 2-day testing window rarely have a systematic way to make these decisions. They rely on tribal knowledge, and tribal knowledge does not scale.
The Traditional Risk-Based Testing Process
The standard approach involves four steps.
1. Identify Risks
Start by listing what can go wrong and what it would cost you. Risks typically fall into three categories:
- Business risk - Revenue impact, customer-facing failures, SLA violations, regulatory non-compliance
- Technical risk - Complex integrations, areas with high code churn, modules with known tech debt
- Historical risk - Features that have produced bugs before, recently refactored code, areas flagged in post-mortems
2. Assess Likelihood and Impact
Score each risk area on two dimensions. A simple 1-3 scale works well to start:
| Likelihood / Impact | Low Impact (1) | Medium Impact (2) | High Impact (3) |
|---|---|---|---|
| High Likelihood (3) | 3 - Medium | 6 - High | 9 - Critical |
| Medium Likelihood (2) | 2 - Low | 4 - Medium | 6 - High |
| Low Likelihood (1) | 1 - Low | 2 - Low | 3 - Medium |
3. Prioritize Test Cases
Map your test cases to risk areas and sort by risk score. High-risk test cases run first. If you run out of time, the tests you skipped were the ones least likely to catch a critical bug.
Here is what this looks like for a typical web application:
| Test Case | Area | Likelihood | Impact | Risk Score | Priority |
|---|---|---|---|---|---|
| Process payment with valid card | Payments | 2 | 3 | 6 | Run first |
| User login with valid credentials | Auth | 2 | 3 | 6 | Run first |
| Search returns relevant results | Search | 2 | 2 | 4 | Run second |
| Export report as CSV | Reporting | 1 | 2 | 2 | Run if time |
| Change avatar image | Profile | 1 | 1 | 1 | Skip this cycle |
4. Execute and Adjust
Run your prioritized tests. After execution, update your risk scores based on what you found. A module that passed cleanly three cycles in a row might deserve a lower likelihood score. A module where you just found two bugs gets bumped up.
This feedback loop is what makes risk-based testing improve over time - each cycle refines your understanding of where risk actually lives.
Where Traditional Risk-Based Testing Falls Short
The framework above works. Teams that adopt it typically reduce regression execution time by 30-40% while catching more critical defects. But it has real limitations.
Risk scores are subjective. Two testers will score the same feature differently based on their experience and biases. There is no ground truth - just opinions informed by memory.
Scores go stale. A risk matrix created at the start of a project rarely gets updated. The codebase evolves, new features ship, developers leave, and the risk profile changes - but the spreadsheet does not.
Manual overhead is real. Maintaining risk scores across hundreds of test cases is tedious work. Most teams start with good intentions and gradually stop updating their matrices because the maintenance cost is not worth it.
Recency bias dominates. Teams overweight the last bug they saw. If authentication broke last sprint, auth tests get bumped to critical even if the root cause was a one-time deployment issue.

These limitations are not reasons to abandon risk-based testing. They are reasons to let AI handle the parts that humans are bad at.
How AI Is Transforming Risk-Based Testing
The core idea of risk-based testing - prioritize tests by risk - does not change with AI. What changes is how you calculate risk and how often you can update those calculations.
Defect History Analysis
Instead of a tester guessing which modules are fragile, an ML model can analyze your entire defect history and identify patterns. Which files have the most bug fixes? Which features generate the most regression tickets? Which areas fail after specific types of changes?
Google famously used this approach to reduce their test suite execution by roughly 90% while maintaining the same defect detection rate. The model learned which tests were likely to fail based on the code changes in each commit, and only ran those tests.
You do not need Google-scale infrastructure to do this. Your test management tool already has the data - execution history, pass/fail rates, defect links. The analysis layer is what is new.
Code Change Impact Analysis
When a developer modifies the payment service, you should re-test payment flows. That is obvious. But what about the order confirmation module that calls the payment service? Or the email notification triggered after a successful payment?
AI can trace these dependencies automatically. By analyzing code changes in a commit (or a set of commits), it identifies which test cases cover the affected code paths and adjusts risk scores accordingly. A test case that covers unchanged code gets a lower priority. A test case that covers the exact function a developer just modified gets bumped to critical.
Intelligent Test Prioritization
Traditional risk scoring is static - you set scores and forget them until someone manually updates them. AI-driven prioritization is dynamic. It considers:
- Historical failure rate of each test case
- Recency and scope of code changes in the tested area
- Defect density trends over the last N sprints
- Correlations between types of changes and types of failures
With the TestCollab MCP server connected to your AI chatbot, you can surface these patterns in plain English:
Find test cases with an unusually high failure rate and map them
to code changes made in the last 7 days.This is surprisingly useful. The test cases that come back are often flaky tests - tests that fail intermittently due to timing issues, environment dependencies, or brittle selectors. Identifying them this way means you fix the flakiness first, before it pollutes your risk data and wastes execution time on false failures. Clean up your flaky tests, and your risk scores become a lot more trustworthy.
Natural Language Risk Identification
This is where things get practical for teams that are already using AI coding agents.
In our recent tutorial on automated test case generation with Claude Code and MCP, we showed how you can point Claude Code at a codebase and have it generate detailed test cases - complete with steps, expected results, and organized suites - directly in TestCollab.
That same conversational workflow applies to risk-based testing. The MCP server already exposes tools for test plans, test suites, and test case management. So you can ask Claude Code something like:
Check the last 5 git commits in this repo. Based on what changed,
create a test plan in TestCollab that prioritizes the test cases
most likely to be affected by these changes.Claude Code will read the diffs, understand which features were modified, match them against existing test cases in TestCollab, and build a risk-prioritized test plan. No spreadsheets, no manual risk matrix updates, no guesswork about which areas need re-testing.
You can take it further:
Look at the test execution history for the last 3 test cycles.
Which test cases have the highest failure rate? Flag any that
cover areas modified in this release and add them to the
regression plan with critical priority.The methods are already there in the TestCollab MCP Server - creating test plans, assigning test cases, setting priorities. The AI agent handles the analysis and decision-making. You stay in control of the final plan.
Implementing Risk-Based Testing: A Step-by-Step Approach
Whether you use AI or not, here is how to get started.
Step 1: Start With Your Highest-Impact User Flows
Do not try to risk-score every test case on day one. Pick the top 10-20 user flows that generate revenue, handle sensitive data, or would cause the most damage if broken. For most applications, these are:
- Authentication and authorization
- Payment and billing
- Core data creation and editing workflows
- Integrations with third-party services
- Data export and reporting
Step 2: Score Each Test Case
Use the Likelihood (1-3) x Impact (1-3) matrix from earlier. Keep it simple. A 1-3 scale forces decisions better than a 1-10 scale where everything ends up as a 7.
Involve both developers and testers in the scoring session. Developers know where the technical risk lives (that function nobody wants to touch). Testers know where the business risk lives (that workflow every customer depends on).
Step 3: Use Historical Data to Validate Your Scores
If you have execution history in your test management tool, pull the pass/fail rates for the last 5-10 cycles. Compare them against your risk scores. You will find surprises - areas you rated as low risk that fail regularly, and areas you rated as high risk that have been stable for months.
Adjust your scores based on the data.
Step 4: Map Risk Scores to Execution Priority
In TestCollab, you can assign priority levels (Critical, High, Medium, Low) to test cases and then filter your test plans by priority. Map your risk scores directly:
- Risk 6-9: Critical priority - always run
- Risk 4-5: High priority - run in every full regression
- Risk 2-3: Medium priority - run when time allows
- Risk 1: Low priority - run only in comprehensive test cycles
Step 5: Recalibrate Every Release
After each test cycle, spend 15 minutes reviewing:
- Did any high-priority tests pass that could be downgraded?
- Did any low-priority tests fail that need to be upgraded?
- Were there production bugs in areas you skipped testing?
If you want a real-time view of how risk translates to release decisions, this is exactly what TestCollab's release readiness dashboard is built for. It aggregates pass rates, open defect counts, and evidence coverage into a live GO/NO-GO verdict - effectively turning your risk-based test results into a release risk score.
Risk-Based Testing in Agile Sprints
The most common objection to risk-based testing is that it is too much overhead for a 2-week sprint. It does not have to be.
In an agile context, risk-based testing is not a formal risk assessment workshop. It is a 10-minute conversation during sprint planning:
The output is a prioritized list of test cases for the sprint's regression cycle. In TestCollab, this translates to creating a test plan with test cases filtered by priority and tagged to the sprint's scope.
For teams using CI/CD pipelines, risk-based test selection can be automated. Your pipeline runs the critical and high-priority tests on every build, and the full regression suite runs nightly or before release.
Measuring the Impact
You will know risk-based testing is working when you see:
- Defect escape rate drops - Fewer critical bugs reach production because you are consistently testing the riskiest areas
- Testing efficiency improves - You find more bugs per test executed because you are not wasting time on low-risk areas
- Release confidence increases - Stakeholders trust the testing process because it is based on data and a clear framework, not "we tested what we could"
Risk-Based Testing, Now Built Into TestCollab
You no longer need a spreadsheet or a separate tool to run the framework above. Risk-based testing is now a first-class part of TestCollab (available on the Enterprise plan).
A dedicated Risks module gives every project a risk register where each risk is scored by likelihood x impact, rolled up into a numeric exposure score, and grouped into colour-coded bands (Low, Medium, High, Critical). Risks link directly to your requirements, test cases, and defects, so you get full traceability from "what could go wrong" to "what we tested and what we found".
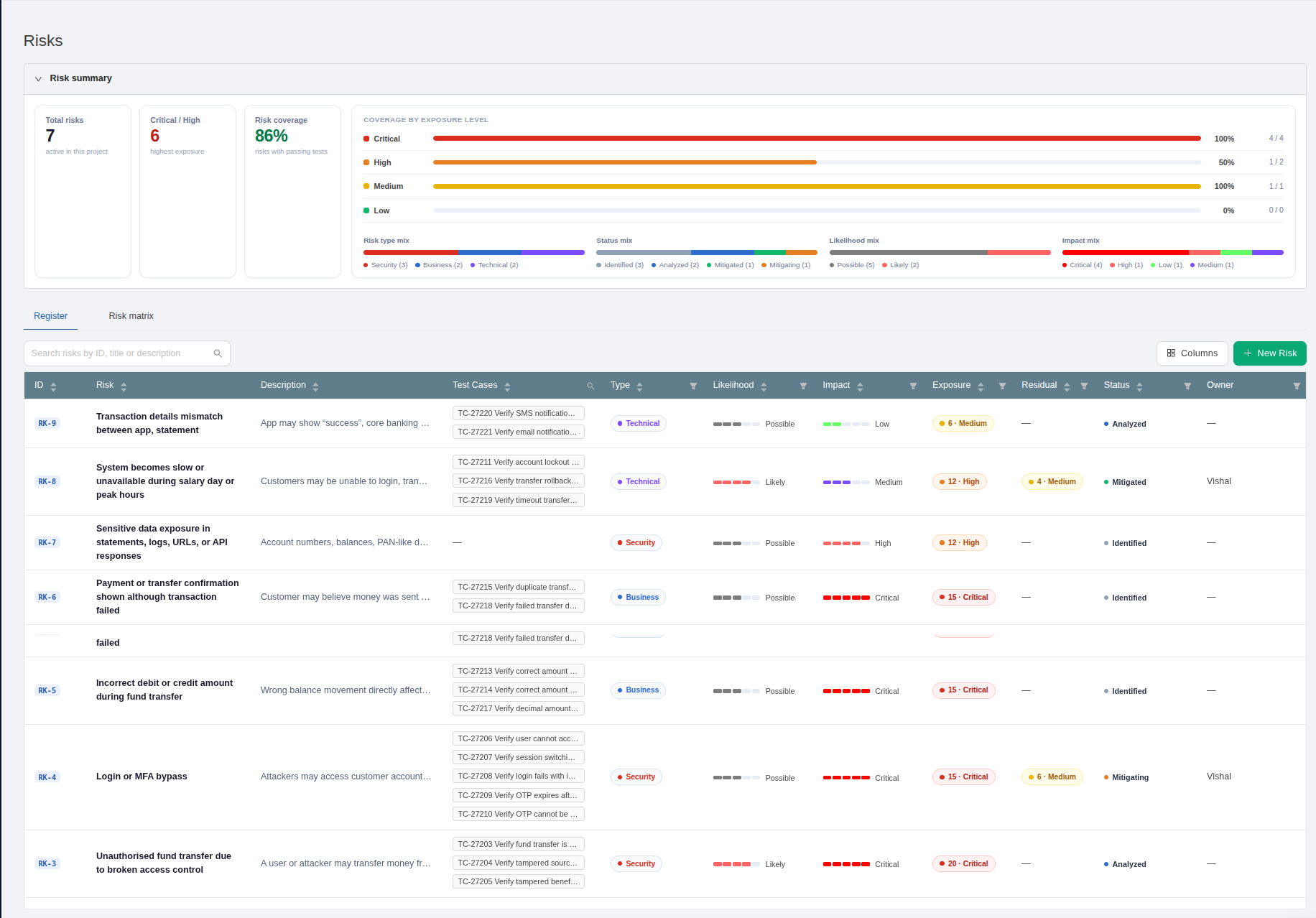
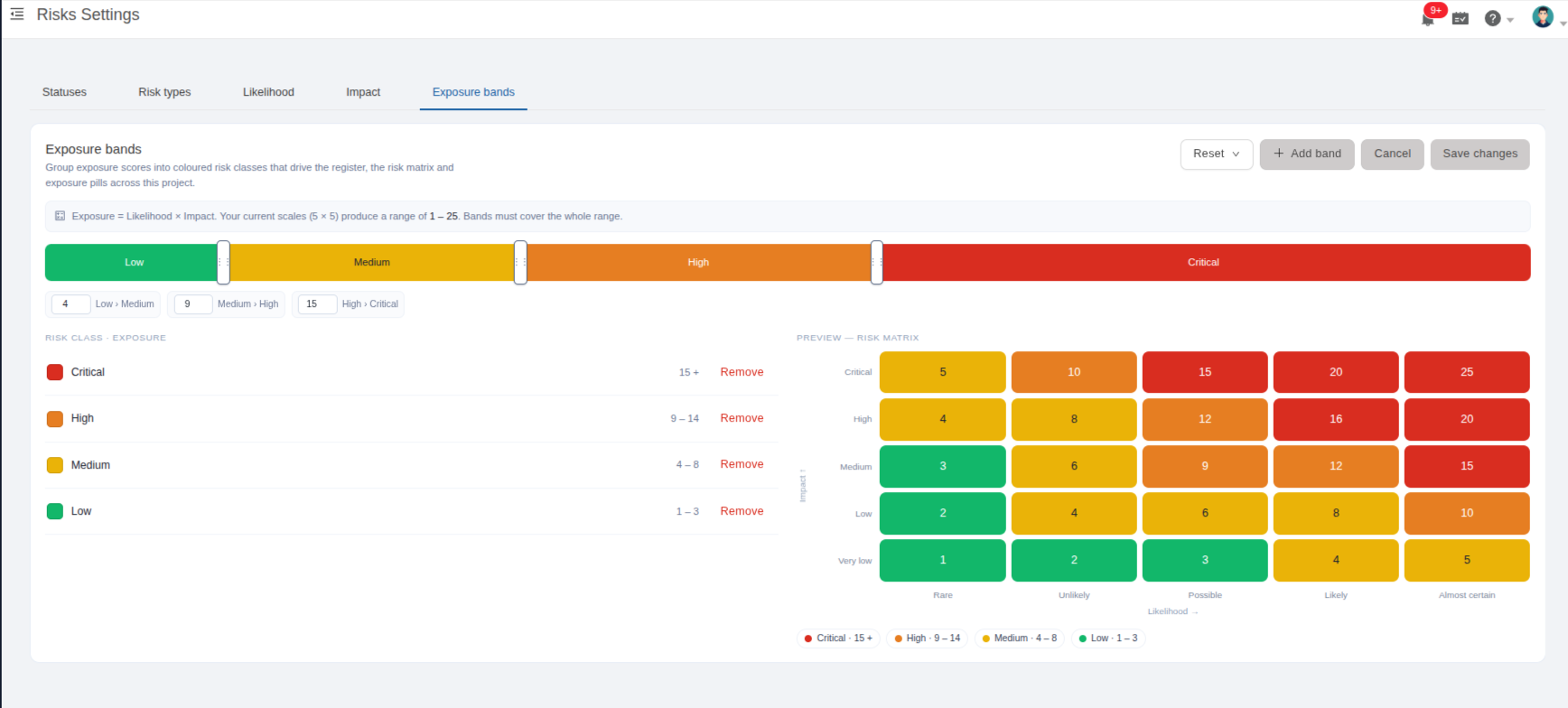
The scoring model is yours to configure. Project admins set the likelihood and impact scales, the risk statuses and types, and the exposure-band thresholds that turn a raw score into a Low, Medium, High, or Critical class. The likelihood x impact matrix gives you the classic heat map, with a live count of risks in each cell.
Most importantly, risk now drives execution. A Risk Level column on your test plans shows each case's highest linked-risk exposure, and you can sort and filter by it so the riskiest cases run first, which is the entire point of risk-based testing. Pair that with the release readiness dashboard and your risk scores feed straight into the GO/NO-GO decision.
See everything that shipped in this release on the changelog.
Getting Started Today
You do not need a perfect risk model to start. Here is the minimum viable approach:
If you are already using TestCollab with the MCP server, you can skip the manual scoring entirely. Ask Claude Code to analyze your codebase and execution history, and let it build a risk-prioritized test plan for you. The tools are already there - the only step is asking.
The shift from "test everything and hope for the best" to "test what matters most based on data" is the single highest-leverage change a QA team can make. Risk-based testing gives you the framework. AI gives you the data to make that framework precise.






