On April 17, 2026, ISTQB released version 2.0 of its Certified Tester AI Testing (CT-AI) syllabus. It is the first major rewrite since 2021, and it does something more consequential than a refresh: it splits AI testing into two distinct disciplines. The new CT-AI is now focused entirely on testing AI systems, while the separate skill of using AI to help you test has moved out into its own certification, CT-GenAI.
That split is the story. Testing AI systems has quietly become one of the hardest problems in QA, and CT-AI v2.0 is the closest thing the industry now has to a shared definition of what "good" looks like. It arrives at exactly the moment the EU AI Act starts turning that definition into a legal obligation. For QA leads, the practical question is not whether to memorize the syllabus. It is how to actually do what it now describes, and how to prove you did. This post walks through what changed, and how teams operationalize each part in a real testing workflow.
What changed in ISTQB CT-AI v2.0
Version 1.0 was written before ChatGPT existed. Version 2.0 reads like it was written by people who have spent the last two years testing large language models in production. Here is what is genuinely new.
The certification split in two. The old CT-AI tried to cover both "testing AI-based systems" and "using AI to do your testing." Version 2.0 drops the second half entirely. Using generative AI to draft, run, and maintain tests is now a separate certification, CT-GenAI. What remains in CT-AI is 100 percent about testing AI and machine learning systems. If your v1.0 study notes were mostly about AI-assisted test generation, they no longer describe this exam.
First-class coverage of generative AI and LLMs. A new section is dedicated to testing generative models, including a hands-on exploratory testing exercise against an LLM. It tackles the problems testers actually hit: the input explosion of prompts, temperature, and context windows; judging correctness and coherence when there is no single right answer; and using a second model as an automated oracle to grade the first.
Red teaming is now an examinable skill. The syllabus defines red teaming as a systematic fault attack to surface harmful behavior: privacy leaks, bias, misinformation, indirect prompt injection, and RAG document poisoning. It explicitly frames this as a growing regulatory expectation under the EU AI Act. Red teaming has moved from AI-safety labs into the standard tester toolkit.
A structure built around the ML lifecycle. The syllabus shrank from 11 chapters to 7 and reorganized around how machine learning systems are actually built and shipped. Two ML-specific test levels now stand on their own: input data testing (bias, representativeness, label correctness, pipeline validation) and model testing (adversarial, metamorphic, drift, A/B, and back-to-back testing). A new chapter covers deployment testing with canary, shadow, and rollback techniques.
Alignment to standards and regulation. Quality characteristics are now mapped to the new ISO/IEC 25059 AI quality model, and references include the EU AI Act. This is what turns CT-AI from a hands-on testing cert into a credible bridge between day-to-day QA and formal AI governance.
A few logistics worth knowing: the exam is still 40 multiple-choice questions in 60 minutes, with a 65 percent pass mark and ISTQB Foundation as a prerequisite. Version 1.0 is retiring (last English exams in April 2027), there is no bridging exam, and existing certificates stay valid. If you are weighing whether the credential is right for your team at all, our take on whether to get your testers certified is a useful starting point.
The gap the syllabus leaves open
Here is the catch with any syllabus: it tells you what to test, at the depth needed to pass an exam. It does not tell you how to run those techniques in a real QA process, how to organize the results, or how to prove to an auditor that you did the work. CT-AI v2.0 is excellent at naming the disciplines. The operational layer is left to you.
That gap is where most teams get stuck. The syllabus says to perform metamorphic testing, drift testing, and red teaming. It does not connect those to your test plans, your release decisions, or your evidence trail. And because testing AI systems is probabilistic rather than pass or fail, the usual habit of "the build is green, ship it" quietly breaks down. You need a place to manage the testing the standard describes, and that place is not the syllabus. Our broader guide on how to test AI applications covers the techniques in depth; this post is about wiring them into a process you can run and defend.
From syllabus to practice: how teams test AI systems
The most useful way to read CT-AI v2.0 is as a checklist of techniques, each of which already has real tooling behind it. The table below maps the main requirements to how teams actually run them, and to where TestCollab fits. We are deliberate about that last column: for the analytical techniques, TestCollab is the system of record that manages, executes, traces, and evidences the tests. It is not a metamorphic engine or a bias scanner, and we will be clear about where that line sits.
| What CT-AI v2.0 requires | How teams actually run it | Where TestCollab fits |
|---|---|---|
| Input data testing: bias, representativeness, label correctness, pipelines | Data validation libraries and frameworks (for example Giskard, Evidently), plus designed manual checks | Author the checks as test cases, run them, and track coverage against requirements |
| Model testing: metamorphic, adversarial, drift, A/B, back-to-back | Metamorphic relation tooling, adversarial generators, drift monitors | Record each run, status, and evidence; tie results back to the feature under test |
| Generative AI and LLM testing, including red teaming | Eval and red-team tooling (for example promptfoo, Garak, PyRIT), human exploratory testing | Organize prompts and attacks as suites; capture screenshots, logs, and outputs as evidence |
| Deployment testing: canary, shadow, rollback | MLOps and release pipelines | Gate the rollout with a release readiness decision backed by test results |
Input data testing
CT-AI v2.0 elevates data testing to its own test level, and rightly so: most model failures trace back to the data. The syllabus asks you to check for bias and disparate impact, confirm the data is representative of real-world conditions, validate label correctness, and test the data pipeline itself. Tools like Giskard and Evidently can profile datasets and surface bias. What they do not do is tell you whether your team has actually covered every data risk for a given feature, or let an auditor see that coverage six months later. That tracking is test management work: each data check becomes a test case, linked to the requirement it protects.
Model testing
This is the chapter that scares teams, because the model has no deterministic expected output. The syllabus answers with a toolkit: metamorphic testing (if the input changes in a known way, the output should change predictably), adversarial testing, drift testing, and back-to-back or A/B comparisons between model versions. It also leans hard on risk-based testing to decide where to spend effort, since you cannot exhaustively test a probabilistic system. The output of all this is a stream of runs and judgments that needs a home: which relations were tested, which version was the baseline, what drifted, and what the team decided to accept.
Testing generative AI and LLMs
The new GenAI chapter is the headline, and it maps directly to work many teams are already doing by hand. Testing an LLM means grappling with non-deterministic output, the test oracle problem (there is no single correct answer), and adversarial robustness. Practical approaches include semantic-similarity checks, using an LLM as a judge, and structured red teaming for prompt injection and jailbreaks. We wrote about this concretely in testing an LLM-based chatbot, where intent classification, false positives, bias, and red teaming all become organized test suites rather than ad hoc prompts. The governance dimension is just as real: bias and fairness work belongs in a deliberate plan rather than a one-off audit. If you need to enforce an AI ethics framework, the tests that enforce it have to live somewhere durable.
Deployment testing
The final chapter is the most MLOps-flavored: canary releases, shadow deployments, rollback testing, and cross-device compatibility. These are about how the model behaves once it is live, not just how accurate it was before release. The natural place for this to land is the release decision itself, where deployment test results become part of a go or no-go call.
The part CT-AI v2.0 leaves to you: governance and evidence
Read the syllabus alongside ISO/IEC 25059 and the EU AI Act, and a theme emerges that no analytical tool addresses on its own: AI testing has to be traceable, repeatable, and auditable. A drift monitor can tell you a model degraded. It cannot show a regulator that every requirement for a high-risk AI system was mapped to tests, executed, and signed off before release. That is a governance problem, and it is the honest center of where a test management platform earns its place.
In practice this looks like three things. First, traceability: every AI-system requirement, whether it lives in Jira, GitLab, or Azure DevOps, mapped to the tests that cover it, with the gaps visible. Second, evidence: screenshots, logs, and run history captured automatically, so a passing result is something you can inspect rather than something you take on faith. We have argued before that capturing test evidence at scale is the difference between a green check and a defensible release. Third, a release decision: a single view where AI-system test results, open defects, and coverage roll up into a go or no-go call, backed by a release readiness dashboard. This is what it means to operationalize the standard. The specialized tools run the techniques; test management is the layer that makes the whole effort coherent and auditable, which is exactly what the EU AI Act will ask for. Our guide to EU AI Act compliance goes deeper on the regulatory side.
To be clear about the boundary: TestCollab does not measure fairness, solve the test oracle problem, or run metamorphic relations for you. It is where you plan those tests, execute and record them, trace them to requirements, and prove the work. That division of labor is the realistic way to practice CT-AI v2.0, not a single magic tool.
The other half: CT-GenAI and using AI in your testing
Remember what version 2.0 removed. The skill of using AI to do your testing did not disappear; it became CT-GenAI. And that half is where AI tooling genuinely shines today, because using AI to draft and run tests is verifiable in a way that "trust the model" is not.
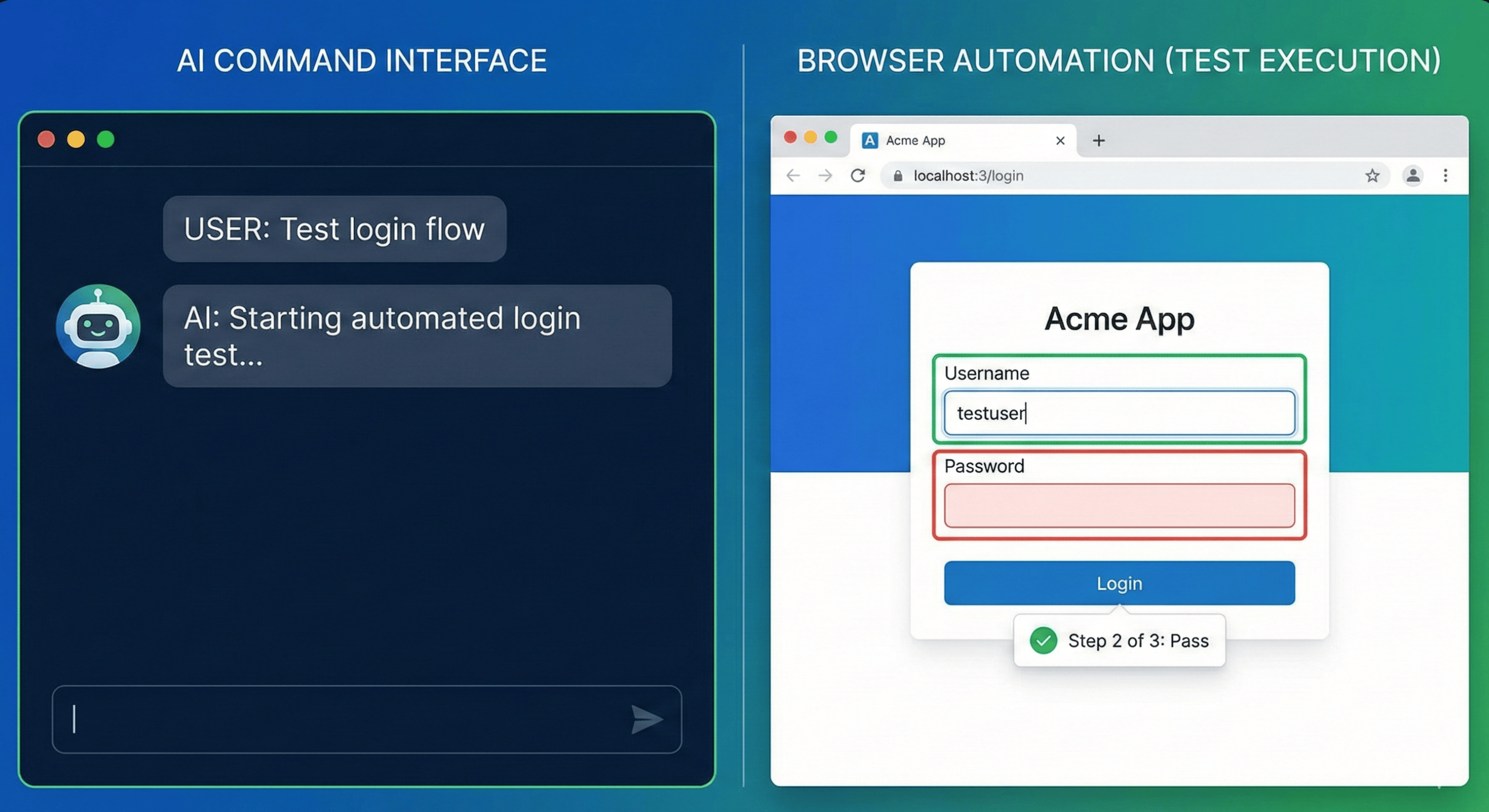
This is the one area where the product does the work directly rather than managing it. QA Copilot generates test cases from requirements, Jira stories, screenshots, and URLs with a human approving every proposal, converts plain-English flows into runnable automation, and self-heals when selectors change. Taken further, AI agents can execute entire test plans through browser automation, observe the result, and capture evidence. If CT-AI v2.0 is about testing the AI, CT-GenAI is about testing with AI, and the two map cleanly onto the two halves of a modern QA stack.
A CT-AI v2.0 readiness checklist for QA teams
Most CT-AI coverage is aimed at individuals sitting an exam. Here is the version for a team lead asking a more useful question: which of these can we run today, and where do we have a gap?
You can likely run today:
- Organizing AI-system tests (functional and non-functional) into managed test plans
- Tracing AI requirements to tests and surfacing coverage gaps
- Capturing reproducible evidence for every run
- Structured red teaming and exploratory LLM testing as documented suites
- A go or no-go release decision backed by test results
- AI-assisted test generation and execution (the CT-GenAI side)
- Automated bias and representativeness analysis on training data
- A repeatable metamorphic testing harness wired into CI
- Continuous drift monitoring with clear re-test triggers
- Non-deterministic oracles (semantic similarity, model-as-judge) standardized rather than improvised
Operationalize the standard, do not just study it
CT-AI v2.0 is the clearest signal yet that testing AI systems is its own discipline with its own techniques, and that regulators will expect evidence you practiced them. The training providers will teach you to pass the exam. The harder and more valuable work is building a process where the testing the standard describes actually happens, gets traced to requirements, and produces proof you can stand behind.
That is the layer we focus on: the place where AI-system tests are planned, executed, evidenced, and turned into a release decision. If you are putting CT-AI v2.0 into practice, start a free trial and see how your AI testing maps to a system of record built for exactly this.